

 融資信息
融資信息
 專題
專題
 鏈上生態
鏈上生態
 詞條
詞條
 播客
播客
 活動
活動
 OPRR
OPRR

如何用 Hermes 修復「AI 味兒」
原文標題:How To Fix AI Slop (Using Hermes)
原文作者:@EXM7777
編譯:Peggy
編者按:AI 生成內容的「垃圾化」,往往被歸因於提示詞不夠好、模型不夠強,或上下文不夠完整。但這篇文章提出了一個更接近工程系統的判斷:問題不在輸入側,而在輸出側。
作者認為,很多人已經反覆嘗試過改寫 prompt、升級模型、開啟記憶、堆疊上下文檔案,但 AI slop 仍會反覆出現。原因在於,這些方法都在優化「生成」本身,卻沒有建立一套穩定的品質控制機制。就像工廠不會只依賴工人的手感來決定產品是否出廠,AI 輸出也不應從模型直接流向用戶,而缺少測試、評分與攔截。
文章的核心方案,是在 Hermes 這個開源 Agent 中搭建一套 eval loop:先定義什麼是「好輸出」,再把標準轉化為可量化的評分體系,並在發布前、運行時和生產環境中持續檢測。無論是內容創作中的空洞表達,還是產品中的幻覺答案、格式錯誤和體驗退化,本質上都是未經測量的 AI 輸出直接抵達受眾。
因此,真正重要的不是再寫一個更長的提示詞,而是補上一層缺失的品質系統。測試案例、評分指標、閾值、回歸測試、審批按鈕和生產環境監控,共同構成了這套機制。它讓「AI 輸出品質」從一種主觀感覺,變成一個可以觀察、比較和修復的數字。
以下為原文:
有些人似乎總能持續交付最好的軟體、寫出精彩的內容,或者生成驚艷的圖像,這背後是有原因的。
他們採用了 eval loop,而你還沒有。
你嘗試過更好的提示詞,換過更貴的模型,寫過更長的指令,打開了記憶功能,也搭建過像小說一樣龐大的上下文檔案,但 AI 垃圾內容還是會一次次出現。
它之所以反復出現,是因為你一直在修補一個本來就沒有壞掉的層。
AI 垃圾內容不是提示詞問題,而是系統問題。就像一家工廠不斷發出有缺陷的產品,問題並不在某個工人,而在品質控制機制:沒有人在產品離開大樓之前檢查它。
所以,這篇文章要搭建的就是這套機制。讀完之後,你將擁有一個可以在 Hermes 這個開源 Agent 中運行的 eval loop:它會在每個輸出發布前,按照你的標準進行評分;在發布後繼續監測真實輸出表現;並把每一次失敗都轉化為新的測試,讓質量底線自動抬高。
我們會一步一步把它搭起來。最終的收益很具體:你可以得到真正乾淨、可信的輸出,不必在半夜重新逐字檢查;你會擁有一個可以直觀看到的質量分數;那些 AI 垃圾內容會在出門前就被攔下,而不是等你的受眾來發現。
你將從這篇文章中帶走這些東西:
為什麼更好的提示詞、更大的模型和記憶功能,始終無法徹底消滅 AI 垃圾內容;以及真正起作用的是哪一層;
AI 垃圾內容藏在你工作中的兩個地方:內容輸出和產品輸出;以及為什麼兩者的修復方式其實完全一樣;
用大白話解釋什麼是 eval loop:這個很少有人日常運行的質量層,以及為什麼從來沒人提醒你去搭建它;
一個本週就能搭起來的質量基準,既適用於內容,也適用於產品:具體要衡量什麼,以及屏幕上的哪個數字才算「好」;
一套完整的搭建步驟:如何用 Hermes 已經提供的組件——skills、memory、cron 和審批按鈕——把整個循環串起來,讓質量閘門自動運行,不再依賴你手動把關。
如果你是衝著「5 個解決 AI 垃圾內容的提示詞」來的,那這篇不是。
那類東西確實存在,但它們並不真正有效。這篇講的是有效的版本。
你幾乎什麼都試過了,除了真正該試的那一個東西。
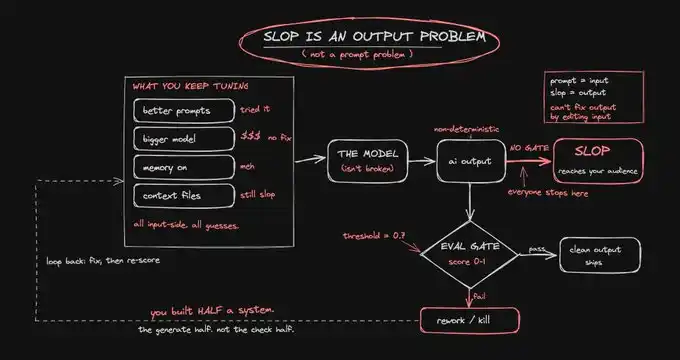
先簡單回顧一下你已經做過什麼:你改寫過提示詞,三次、四次;你加入了示例,加入了人設,加入了一長串「不要這樣做」的清單。你升級到了前沿模型,每個 token 多花了 5 倍的錢,結果輸出只是變得更自信了,卻並沒有變得不那麼空泛。你打開了記憶功能,搭建了上下文檔案,把你的品牌語氣、過往作品、風格指南都餵給了它。
這些操作中的每一個,都會給你換來幾次不錯的生成結果。然後,AI 垃圾內容又會慢慢爬回來。
因為所有這些,都是輸入側的修補。你一直在打磨那個「生成」的東西,卻忽略了真正應該負責「攔截」的東西。再好的槍,如果只是朝黑暗中開火,也依然什麼都打不中。
AI 垃圾內容是一個輸出側問題。問題不在於模型不能產出好作品,而在於你沒有辦法在它到達重要的人面前,提前分辨哪些是好作品,哪些是壞作品。
你沒有 eval loop,沒有品質基準,沒有記分牌。所以你一直是在盲調。你改了一個提示詞,感覺它好像變好了,但感覺不是測量,感覺也攔不住接下來 50 次生成裡藏著的那一次糟糕輸出。
於是你開始責怪自己,責怪提示詞,責怪 Agent 設置,責怪上下文工程。但真正缺失的,是一整層你從來沒有被教過的 AI 工作方式。而讀完這篇文章後,這一層會在你自己的機器上、在 Hermes 裡跑起來。
為什麼更好的提示詞解決不了這個問題,以及為什麼大家仍然一直在嘗試
提示詞是一種假設,輸出是結果,而 eval 是唯一能把兩者閉環連接起來的東西。
沒有這個閉環,你就會永遠停留在猜測裡。你調整假設,肉眼看一條結果,然後宣佈勝利。你永遠不會發現,同一個提示詞其實有 30% 的時間會產出垃圾,因為你每次只看眼前這一條輸出。
模型是非確定性的。同一個提示詞運行兩次,會給出兩個不同答案。這意味著,即便是一個「完美」的提示詞,也會在某個比例的運行中產出 AI 垃圾內容。而在客戶或用戶真正看到它之前,你根本不知道是哪一次。
所以,一個完美提示詞並不是品質保證,它只是一次勝率稍高的拋硬幣。而你現在是在把每一次拋硬幣的結果都直接發出去。
大家之所以一直把希望寄託在提示詞上,原因很簡單:提示詞是你唯一看得見的槓桿。你可以編輯它,而編輯它會讓你產生一種掌控感。
測量則是隱形的。沒有人賣給你一門關於測量的課程,也沒有人會發一條病毒式傳播的帖子,標題叫「這個 eval suite 讓我的輸出品質提升了 10 倍」。於是,整個討論都被困在了那個單獨使用時根本解決不了問題的槓桿上。
那些 AI 輸出始終乾淨的人,並不是比你更會寫提示詞。他們只是多了一個你沒有的槓桿:他們會在每個輸出發布前,用一套標準去衡量它。正是這種衡量機制,讓他們的提示詞看起來像魔法。
AI 垃圾內容藏在兩個地方
AI 垃圾內容只藏在兩個地方,而幾乎所有人都只盯著其中一個。
第一個地方,是你的內容輸出。
推文、文章、郵件、落地頁、貼文,任何你用 AI 生成並以自己名義發布的東西,都屬於這一類。
這裡的 AI 垃圾內容,看起來往往是「技術上沒錯,但完全空心」的作品。它聽起來像時間線上每一個 AI 帳號發出來的東西:外表正確,內裡空洞。
它會在公開場合失效,而你甚至說不清為什麼,因為你按下發送鍵時,每一篇單獨看起來都還可以。
第二個地方,是你的產品輸出。
你上線的 AI 功能、Agent、聊天機器人、客服回覆器、資訊擷取流水線,任何使用者真正會接觸到的東西,都屬於這一類。
這裡的 AI 垃圾內容,可能表現為一個帶著絕對自信的錯誤答案,一個幻覺出來的數字,一個損壞的 JSON 輸出,一種不符合品牌的語氣,或者一個在展示時表現很好、卻在三次部署之後悄悄退化的輸出。
它不會在公開場合立刻死掉。它會在沉默中擴散。每個使用者都得到一個稍差一點的體驗,而大多數人永遠不會告訴你。他們只會離開。
這兩者是同一種病,解法也相同。
內容垃圾和產品垃圾,本質上都是未經測量的 AI 輸出,中間沒有任何質量閘門,就直接被送到了受眾面前。
唯一的區別,是風險和可見度。內容垃圾會讓你在公開場合尷尬,產品垃圾則會悄悄消耗你的業務。而我們將在 Hermes 裡搭建的這個循環,會用同一個 skill 來給兩者打分。這樣,你就可以用一套質量系統管理所有生成內容,而不是為不同場景維護兩套系統。
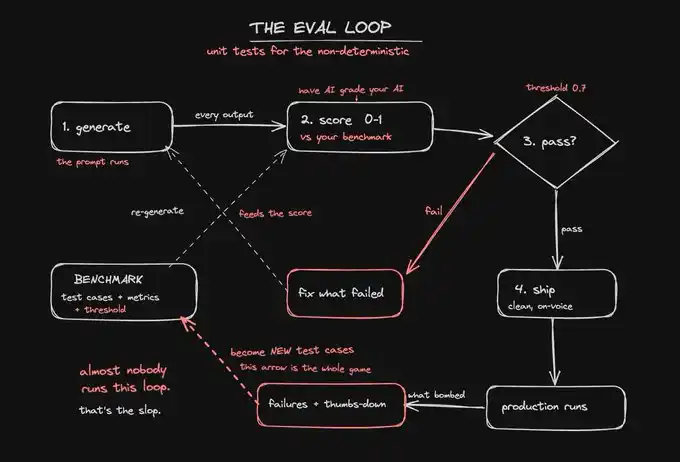
eval loop 到底是什麼
eval loop,就是一個可重複運行的測試。它會在 AI 輸出發布前和發布後,自動將其與你定義的標準進行對照,並給出評分。
就這麼簡單。這就是全部。而它正是大多數 AI 構建者缺失的那一層。
生成輸出 根據你定義的基準進行評分攔截低於標準線的結果 修復失敗的部分 重新評分,並且只讓通過測試的輸出進入下一步
軟體工程師很早就擁有這套機制,它叫測試。你絕不會在沒有測試的情況下直接發布程式碼,然後祈禱它能在生產環境裡正常運行。但這正是現在整個行業發布 AI 輸出的方式:從模型直接到用戶,全靠感覺和祈禱。
幾乎沒有人擁有 eval loop,原因其實和人群結構有關。今天使用 AI 構建東西的人,很多來自內容、銷售、產品、創業,而不是工程背景。所以,「為你的輸出寫測試」從來不在他們的工具箱裡。eval 聽起來像是「真正的工程師」才會用的基礎設施,而最需要它的人,反而會下意識覺得自己沒有資格使用它。
你可以把它理解為一種面向非確定性系統的單元測試。你測試的不是程式碼能不能運行,而是輸出是否足夠好。你要在足夠多的案例上進行測試,確保某一次糟糕生成不會輕易藏過去。
一個 eval loop 會運行在三個地方。接下來我們要搭建的系統,會把它放進這三個環節裡:
發布前,用保存好的案例集測試你的新提示詞或新模型,確認它沒有變差。這就是回歸測試,用來防止一個改動修好了一處問題,卻悄悄弄壞了另外三處。
運行時,在輸出生成的過程中進行評分,並讓條件邏輯在失敗結果抵達用戶之前攔下它。這就是護欄。
生產環境中,持續抽樣真實執行結果並進行評分,這樣你能在質量開始下降的當天就發現問題,而不是等到一周後客戶來投訴。
第一種,你甚至可以用電子表格搭起來。但如果想讓這三種測試持續運行,同時又不把它變成你的第二份工作,這正是我們要把它放進 Agent 裡的原因。
一旦品質變成一個數字,AI 垃圾內容就不再是你反覆產生的一種感覺,而會變成一個可以修復的 bug。你無法調試一種感覺,但你可以調試一個從 0.82 掉到 0.61 的分數。
基準:你接下來要搭建的三個部分
一個 benchmark 有三個組成部分。無論你是在評估內容,還是在評估產品,它們都是同樣的三件事:
測試案例:真實輸入,以及與之對應的優質輸出樣本,也就是你的 ground truth 指標:你如何把一個輸出轉化為分數,最好是 0 到 1 之間的分數 門檻:低於這條線的內容一律不允許發布
把這三件事搭起來,你就擁有了一個品質閘門。少掉任何一個,你擁有的都只是一個願望。接下來這一節會說明,每個部分裡應該放什麼,然後我們會把這三部分全部接入 Hermes。
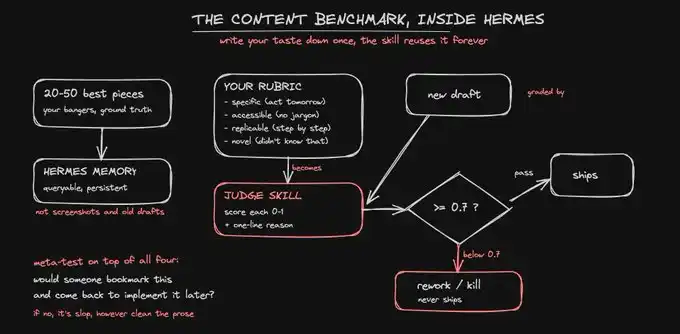
對於內容來說,你的測試案例就是你的黃金標準。
找出你最好的 20 到 50 篇作品:那些真正表現好的內容,那些被收藏的貼文,那些你願意完整署上自己名字的文章。這就是「好」的樣子。你不是在憑空發明一套標準,而是在提取你已經在最好狀態下達到過的標準。
對於內容來說,你的指標就是一套評分量表。
一個分數是否可靠,取決於它背後的評分量表是否可靠。所以,你要把自己真正相信的「好內容標準」編碼進去。對於內容,我會從四個標準給每一篇作品打分:
它是否解釋了某件具體事情該怎麼做,而不是只提供一種感覺;讀者明天就能採取行動。
目標受眾是否都能看懂;沒有術語牆,也沒有只有圈內人才懂的表達。
它是否結構清晰、可重複使用、按步驟展開,而不只是勵志。
它是否足夠新穎;讀者此前並不知道這件事可以這樣做。
覆蓋在這四個標準之上的元標準是:讀者會不會收藏這篇內容,並在之後回來照著執行?
如果答案是否定的,那無論文字讀起來多乾淨,它都是 AI 垃圾內容。
關鍵在於評分量表本身。一個模糊的量表,比如「這篇內容好嗎?有吸引力嗎?」,只會產生模糊的分數。一個具體的量表,比如「這篇內容是否至少包含一個可以直接複製使用的模板或操作手冊?」,才會產生你可以信任的分數。只有當你真的把自己的品味寫下來,judge 才能繼承你的品味。
對於產品來說,測試案例來自你的日誌。
你要從日誌、真實用戶會話中提取你的功能真正遇到的輸入,而不是只拿上線當天測試過的三個 happy path 示例。真正會擊穿系統的,往往是那些奇怪的案例,而這些奇怪案例都藏在你的日誌裡。
對於產品來說,指標要匹配任務本身。
針對每一個輸入,定義什麼樣的輸出才算正確,然後讓指標與任務類型匹配。如果只有一個正確標籤,就用精確匹配;如果結構必須成立,就用驗證器;如果輸出是開放式的,就用語義相似度加 judge。指標只需要做到一件事:返回一個數字。因為只有數字,才能放進閾值裡。
對於內容和產品來說,閾值就是你要守住的那條線。
0.7 是一個合理的起點。任何低於 0.7 的內容,都必須在發布前被重做或丟棄,沒有例外。閾值只有在你永遠不會因為「我挺喜歡這條」就放過一個 0.6 的結果時,才真正有效。它的意義,就是把深夜裡那個帶著自我投射的判斷從決策中拿掉。
這就是 benchmark。現在,我們要讓它自己運行起來。
在 Hermes 里搭建這個循環
Hermes 並沒有自帶一個 eval 按鈕,也沒有一個叫「質量」的儀表板,讓你點擊「開啟 AI 垃圾內容防護」。
但 Hermes 給你的東西其實更好:它給了你 eval loop 的原始組件。你只需要把這些基礎能力組裝一次,就能真正擁有它。
這些組件包括:它能自己編寫並重複使用的 skills,會跨會話增長的持久記憶,內建的 cron,可以發送到任何平台的交付能力,Slack 裡的審批按鈕,以及寫進核心機制裡的自我改進習慣。
Hermes 稱自己為「會和你一起成長的 Agent」。而這種成長,正是我們要搭建的循環。
所以,我們開始接線。一共六步。
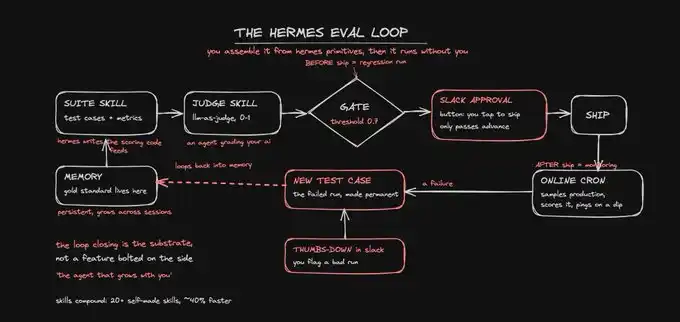
第一步,把 Hermes 部署到它能夠觸達你的地方。
安裝 Hermes,並將其接入 Telegram。這一點比聽起來更重要,因為品質閘門只有在能夠打斷你時才真正有效。Hermes 可以運行在 20 多個渠道上,並能在 Slack 和 Telegram 中原生推送審批按鈕。也就是說,Agent 可以在後台完成工作,並在需要你做決定時輕輕拍一下你的肩膀。
第二步,將你的黃金標準加載進記憶。
Hermes 擁有可以跨會話增長的持久記憶,並支持完整的跨會話召回。所以,你 benchmark 中那 20 到 50 篇最好的作品,只需要放進去一次,就會一直保留在那裡。
這部分內容通常會分散在截圖、舊草稿和零散文件裡。但在這裡,它會成為 Agent 的長期記憶,是可查詢的,也是評分時用來對照的 ground truth。
第三步,將你的評分量表變成一個 judge skill。
這是整個系統的核心。你只需要用自然語言告訴 Hermes 一次:創建一個 skill,接收一段輸出和你的評分量表,然後針對每一項標準返回一個 0 到 1 的分數,並附上一句理由。
這就是 LLM-as-a-judge:讓一個 Agent 來評估你的 LLM 輸出。配合一套清晰鋒利的評分量表,模型會成為一個比你更穩定的批評者。因為它沒有自尊心,也不會捨不得刪掉那句你暗自得意的句子。
之所以要把它做成 skill,而不是一次性的提示詞,是因為 Hermes 的 skills 本質上是程序性記憶。Agent 會編寫它們、保存它們,並反覆複用它們。你只需要把自己的品味編碼一次,它就可以持續為之後的每一次輸出打分。
而且,skills 是會複利的。Nous 發現,擁有 20 多個自創建 skills 的 Agent,在完成類似任務時速度會提高 40%,因為它們不再需要反覆重新發現流程。你的 judge 也會在運行得越多時,變得越鋒利。
第四步,將測試套件做成一個 skill,而不是一張表格。
你的測試案例和指標函數,會一起變成一個由 Hermes 保存並進行版本管理的 skill。指標庫則根據具體任務來決定:分類任務用精確匹配;萃取任務用正則表達式;結構化輸出用 JSON 校驗器,以及 key-value 校驗器;生成式輸出則用語義相似度。
對於那些開放式任務,就使用你的 judge skill。Hermes 會自己編寫評分碼。你只需要描述任務,它就會搭建相應的指標。所有這些都放在一個地方,由 Agent 自己管理,而不是散落在一張你遲早會找不到的表格裡。
第五步,用回歸測試和審批按鈕守住發布關口。
這是整個系統裡杠杆最高的習慣,也是最沒人能長期手動堅持的習慣。所以,我們把它交給 Agent。
把流程接好之後,任何改動——新的提示詞、替換的模型、調整過的流水線——都會自動觸發測試套件。Hermes 會重新跑一遍所有案例,計算相較於基線的分數變化,然後不會悄悄發布,而是會在 Slack 裡提醒你:「分數從 0.81 降到了 0.74,有兩個案例出現回退,要批准嗎?」
只有當你點擊審批按鈕之後,它才會繼續推進。
你可以用 /goal 把它持續鎖定在這個任務上,讓 Agent 跨多輪對試始終圍繞同一個目標執行。對於更大的任務,它的多 Agent 看板還能把運行流程拆解開來,並行評分,再安排執行時間。
這樣,品質閘門就會變成一個常駐流程,而不是一件你必須記得手動去做的事。
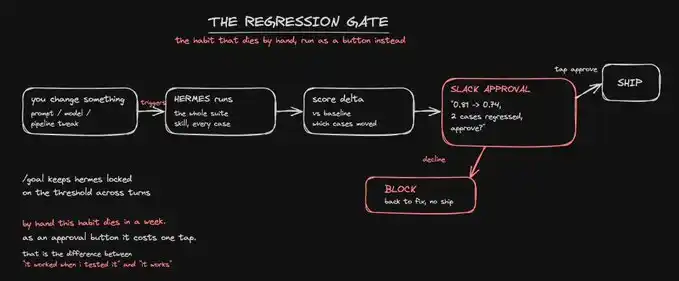
第六步,用 cron 監控生產環境,並完成閉環。
Hermes 內建 cron,可以把結果發送到任何平台。因此,你可以安排一個定時任務,抽樣真實執行結果,用同一個 judge skill 給它們打分,並在分數跌破標準線的那一刻私訊提醒你。
這樣,你能在品質開始下降的當天就發現問題,而不是等到一周後客戶來投訴。
「eval 分數下降了」,這是一個你可以立刻處理的問題;「某個客戶好像有點不高興」,則不是。
接下來,是讓整個系統開始複利的關鍵部分。
當你在 Slack 裡對某個糟糕輸出點下 thumbs-down,Hermes 會把它寫回測試套件 skill,作為一個新的測試案例。那次失敗的執行會變成一個永久檢查項。
而且,由於自我改進是 Hermes 的核心機制,而不是後來外掛上去的功能,這套測試套件會每週自動變得更堅固。
你睡覺的時候,質量底線也在繼續抬高。
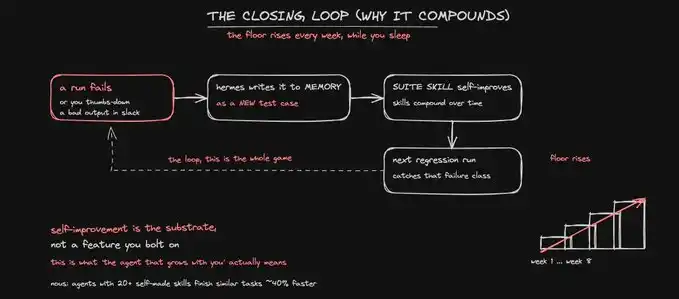
這套系統真正跑起來之後,好的狀態會非常具體:一篇內容如果在你的評分量表中低於 0.7,就永遠不會被發布。一次產品改動如果讓任何指標跌破基線,就會阻止部署,直到你親自批准。
而生產環境中的分數線會保持平穩,或者持續上升。它開始下跌的那一天,就是 Hermes 提醒你的那一天,而不是等到一周後用戶流失數據才顯現出來。
沒人想聽的部分
你的 AI 輸出之所以不穩定,不是因為你不會寫提示詞,也不是因為模型還不夠聰明。
而是因為你只運行了生成步驟,卻沒有運行質量步驟。你搭建的是半套系統,卻一直在責怪那半套真正起作用的部分。
修復方式不是換一個更好的提示詞,而是補上缺失的那一層。
定義什麼是好,把它變成一個數字,用這個數字評估每一次輸出,攔住所有低於標準線的結果,並完成閉環,讓質量底線每週自動抬高。
現在,這一層不再是某個「以後再做」的項目,而是在你自己的機器上、通過一個 Agent、用六個步驟就能跑起來的系統。
做到這一點之後,AI 垃圾內容就不再是隨機發生在你身上的東西,而會變成每次出門前都能被你攔下的東西。就像一家真正的工廠,會在缺陷產品抵達客戶之前就把它截住。
提示詞從來不是系統。
eval loop 才是系統。Hermes 是它運行的地方。
現在,你已經擁有它了。
[原文鏈接]
歡迎加入律動 BlockBeats 官方社群:
Telegram 訂閱群:https://t.me/theblockbeats
Telegram 交流群:https://t.me/BlockBeats_App
Twitter 官方帳號:https://twitter.com/BlockBeatsAsia






