

 融資信息
融資信息
 專題
專題
 鏈上生態
鏈上生態
 詞條
詞條
 播客
播客
 活動
活動
 OPRR
OPRR

Karpathy加入Anthropic,对Claude意味着什么?
原文標題:What Karpathy Joining Anthropic Actually Means For Claude
原文作者:@nateherk
翻譯:Peggy,BlockBeats
編者按:Andrej Karpathy 加入 Anthropic,並不只是「AI 大牛加入頂尖實驗室」的人事新聞。更值得關注的,是這次人事變動背後所指向的產品方向變化。
過去一年,AI 行業的競爭焦點仍大量集中在模型本身:誰的 benchmark 更高,誰的推理能力更強,誰在排行榜上領先。但隨著 Claude Code、Skills、MCP、項目記憶、Agent 工作流等產品能力不斷完善,一個更清晰的趨勢正在出現:模型本身只是產品的一層,真正決定用戶產出效率的,是包裹模型的上下文、記憶、工作流、技能、連接器、文件結構、風格指南和目標迴圈。
Karpathy 過去幾個月反覆強調的「context engineering」,正好對應了這一變化。真正決定 AI 能否產生穩定價值的,不只是用戶寫下的一條 prompt,而是模型能否理解你的文件、工作流、風格標準、業務目標和判斷體系。換句話說,AI 的下一階段競爭,可能不再只是「誰的模型更強」,而是誰能讓模型更好地進入真實工作場景。
從 LLM Wiki 到 AutoResearch,再到 /goal 這類目標驅動式迴圈,Karpathy 公開探索的方向一直圍繞同一個問題:如何讓 AI 從「回答問題的聊天視窗」,變成一個能理解上下文、持續執行任務、圍繞目標迭代的工作系統。而 Anthropic 最近在 Claude Code、企業服務、生態連接器和工作流能力上的佈局,也正沿著同一條路徑展開。
因此,Karpathy 加入 Anthropic 的意義,不只是一次人才流動,而像是對 Anthropic 產品路線的一次註腳:未來的 AI 工具,價值不只在模型參數裡,也在用戶沈澱的數據、工作流、記憶系統和行業知識中。誰能把這些上下文組織起來,誰就可能真正把 AI 從「工具」推向「基礎設施」。
以下為原文:
幾個小時前,Andrej Karpathy 發文宣布,他將加入 Anthropic。
這個故事最簡單的版本是:一位 AI 大佬加入了一家大型 AI 實驗室。
但更值得關注的問題是:為什麼是 Anthropic?又為什麼是現在?
因為只要你回頭看 Karpathy 過去幾個月持續公開搭建的東西,再看看 Claude Code 最近不斷推出的功能,就會發現兩者似乎早已在朝著同一個產品方向靠攏。
背景
Karpathy 是現代 AI 領域最重要的人物之一。
他是 OpenAI 2015 年的創始成員之一,曾在 Tesla 負責 AI 業務五年;2023 年回到 OpenAI,一年後離開;隨後創辦了自己的 AI 教育公司 Eureka Labs。他還推出了 LLM 101n,這是一門免費課程,教用戶如何從零開始構建一個語言模型。
他也是「vibe coding」這個概念的提出者:你只需要用英文描述自己想要什麼,讓 AI 來寫程式碼,然後不斷感受、引導、迭代。他還提出了「context engineering」(上下文工程)這一概念,這將成為本文後續討論的關鍵。
所以,這並不只是一次普通招聘。它意味著 AI 領域最具影響力的聲音之一,加入了當下勢頭最強的 AI 實驗室之一。
Claude Code 已經成為許多 builder 在構建 Agent、寫程式碼,或處理真實知識工作時優先選擇的工具。大約一周前,Ramp 發布了其 AI 指數。根據這份數據,Anthropic 在企業採用率上首次超過 OpenAI:34.4% 對 32.3%。
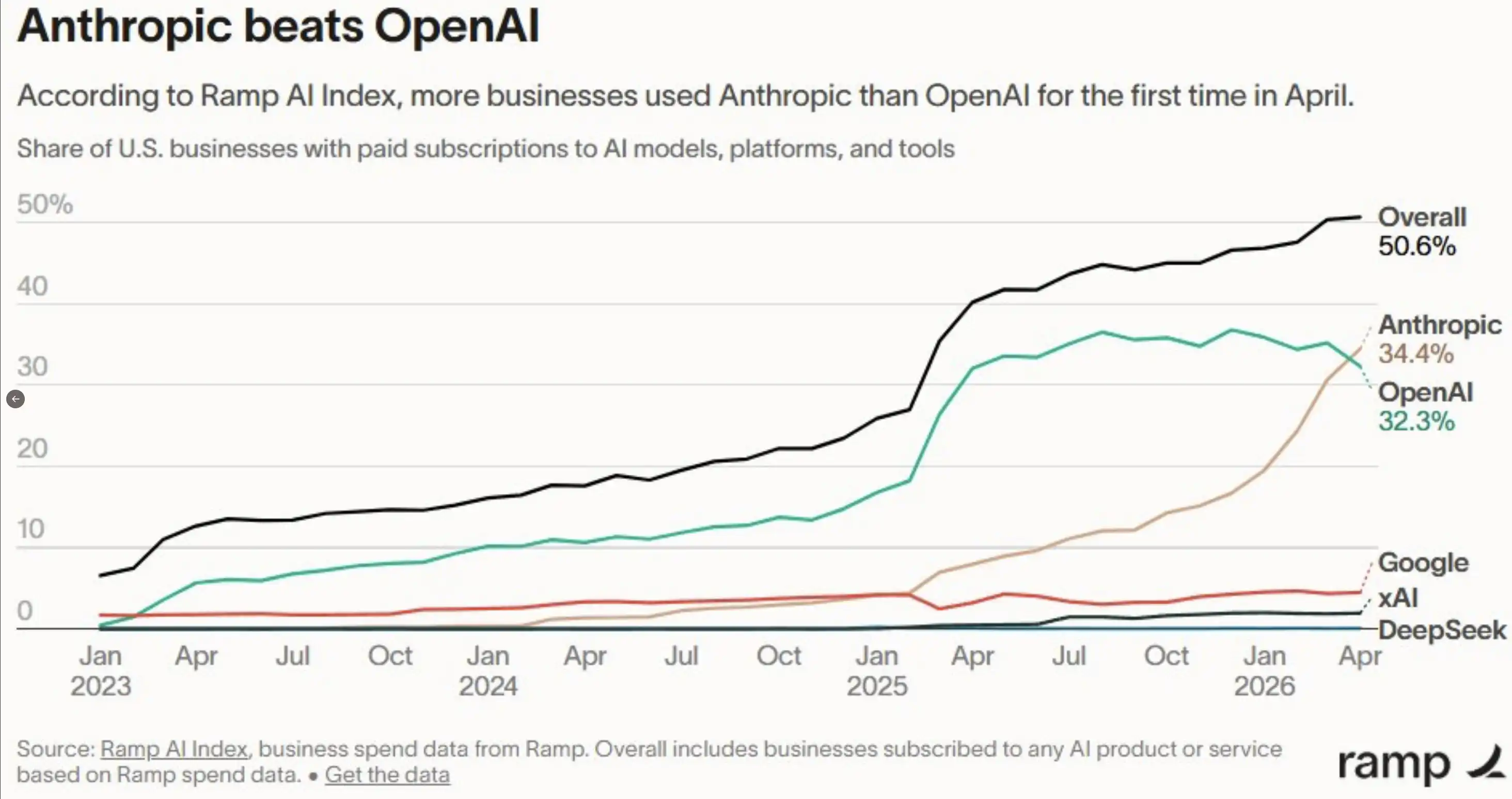
當然,公平地說,這只是 Ramp 客戶群體裡的數據。OpenAI 仍然擁有強大的消費者品牌,也有大量企業級合同沒有被納入這組樣本。我不想過度放大這件事,但這個信號確實很難忽略。
本月初,Anthropic 还宣布成立一家新的企业 AI 服务公司。这是一家由 Anthropic 与 Blackstone、Hellman & Friedman、Goldman Sachs 共同组建的合资企业,旨在帮助中型企业将 Claude 引入核心业务流程。
再看一次这一举措:他们正在开发模型,同时还在开发产品入口,例如 Claude Code、Skills、MCP;他们正在构建合作伙伴网络;现在又增加了一层服务能力,帮助企业真正实现产品落地。
这已经不再是「给你一个模型,然后自行解决剩下的事情」的游戏。
封套才是产品
如今,大多数关于人工智能的讨论仍将模型本身视为一个完整的产品:哪个模型在哪个基准测试中获胜,Opus 4.7、GPT-5.5、Gemini 哪个更强大,排行榜发生了什么变化。
模型当然很重要,我并不是在说模型不重要。但随着这些工具的使用时间越长,人们越来越明显地感到:模型只是产品的一部分。真正改变你日常产出的是模型外部的封套。
这也解释了为什么两个人使用同一个模型,却最终得到完全不同的结果。
所谓的封套就是决定模型如何被使用的一切。
→ Claude Code 本身、Codex、Skills、子代理、Hooks、MCP 连接器。
→ 你的 CLAUDE.md、你的记忆、你的文档、你的用例。
→ 你的文件结构、你的风格指南,以及你对「好结果」的真实定义。
这就是模型所处的环境。
如果你打开一个全新的聊天窗口,没有任何上下文,然后让它帮你处理业务问题,它对你一无所知,只能猜测。因此,你只能一遍又一遍地在对话中解释那些你已经说过十次的背景信息。
但如果你提供给它你的文件、用例、工作流程、风格指南和真实的成功标准,同一个模型,结果将完全不同。
这正是 Karpathy 与 Anthropic 的契合之处。他提出「context engineering」(上下文工程)而不是继续停留在 prompt engineering(提示工程),原因就在于此。真正重要的能力不是构建一个完美的提示,而是搭建一个正确的环境,让模型能够真正发挥作用,并在不同对话之间记住和应用上下文。
Anthropic 一直在悄悄構建這個環境。Karpathy 一直在公開教授這種方法。現在,這兩套理念匯入了同一家公司。
一旦這樣理解,Karpathy 過去幾個月公開做的事情,就不再像是一組隨機項目,而更像是一張路線圖。
LLM Wiki 與你的數據護城河
今年 4 月,Karpathy 發布了 LLM Wiki。這個項目很快在 X 上火了。
它的結構非常簡單。如果你想了解,我也做過一個完整的YouTube 教程
→ 一個 raw/ 文件夾,裡面放大量 markdown 文件,可以是筆記、資料來源、轉錄稿,任何材料都可以。
→ 一個 wiki/ 文件夾,由 Agent 綜合整理所有內容,建立材料之間的連接,並生成思維導圖。
→ 一個 schema 文件,類似 CLAUDE.md 或 AGENTS.md,用來告訴 Agent 這個系統如何運作,以及如何吸收新材料。
它不是讓 AI 去搜索原始文件,也不是簡單跑一次向量查詢,而是讓 AI 構建一個活的、不斷演化的知識庫。它會閱讀資料,理解資料之間的關係。很多人開始用它搭建自己的「第二大腦」。
這件事比表面看起來更重要。很多人說「數據是護城河」時,腦子裡想到的是某個巨大的企業數據庫。但對普通 builder 來說,真正的護城河更小,也更實際。
它可能是你的會議筆記、內部 SOP、客戶電話記錄、轉錄稿、你隨手使用的命名規範,以及那些真正屬於你的工作框架。
如果 Claude 能把這些內容轉化為模型可見、可用的上下文,那麼對你而言,這個模型每周都會變得更聰明、更有用。
這就是鎖定效應。不是因為你不能換模型,你當然可以換。但當你在某一個工具裡持續構建上下文、工作流和記憶,時間越久,就越難離開。
LLM Wiki 不只是一個副項目。它是一個線索。我不會驚訝於未來 Claude Code 或 Claude 項目記憶中出現更原生版本的類似功能。你已經可以在 auto-dream 功能裡看到一些苗頭。
當然,你不必等。這個週末你就可以自己動手,讓 Claude Code 讀取你的重要文件,並按這種方式構建一個 wiki。
如果你想成為 AI-first 的人,你的數據只有在 Agent 知道如何找到它、如何正確使用它時,才真正有價值。
AutoResearch 與 /Goal 迴圈
今年 3 月,Karpathy 發布了一個叫 AutoResearch 的專案。它是一個自動化研究迴圈。如果你玩過 Ralph Loop,會發現兩者在思路上有些相似。
它的模式大致是:
1、拿到一個訓練腳本。
2、提出一個修改方案。
3、跑一次短訓練任務。
4、根據客觀指標檢查結果:通過還是失敗。
5、不斷重複,直到達成目標。
坦白說,AutoResearch 並不是我個人高頻使用的功能。我不訓練模型,也不構建那種需要這類迴圈的應用。但它的形態很重要。
定義目標。讓 Agent 去工作。完成後再回來。
再看整個生態最近在推出什麼:Codex 有了 /goal,Hermes 有了 /goal,Claude Code 也有自己的原生 /goal。
我不是說 Karpathy 親自發明了這個功能。我不知道。而且從底層看,AutoResearch 和 /goal 也不是一回事。但它們的模式顯然相關。
兩者都在把我們從「一個 prompt,一個回答」的模式中帶出來。
它們正在把我們推向另一種互動方式:設定結果,讓 Agent 自己決定怎麼做,等條件滿足後再回來。
這就是加強版 vibe coding。定義「要什麼」,不要定義「怎麼做」,然後等它完成。
一旦把這個模式和 LLM Wiki 的思路結合起來,整個東西就不再像聊天機器人了。它開始像一個真正的員工:理解你的業務,並圍繞一個目標持續工作,直到目標達成。
教育這條線索
Karpathy 的加入公告裡,有一句話值得放大來看。他說:「我依然對教育抱有深厚熱情。」
Eureka Labs,也就是他上一家公司,本質上就是一個教育項目。它的目標不是教人「點擊這個按鈕、連接這些節點」,而是幫助人們從內部真正理解 AI:這些系統到底是如何運作的。
Karpathy 很少見的一點在於,他能把極其技術化的東西講得讓人覺得可以理解、可以接近。懂一件事是一種能力。把它教到別人真正能用,是另一種完全不同的能力。
這對 Anthropic 很重要。如果下一階段的競爭圍繞的是上下文、工作流、Skills、記憶和循環,那麼瓶頸不只是技術,也包括教育。
IBM 最近一項關於 AI 採用和變革管理的研究,就清楚展示了企業「能用上 AI」和「真正用好 AI」之間的巨大差距。大多數企業都會卡在這個地方。
讓一位最擅長 AI 教育的人進入組織,幫助縮小這個差距,這絕不是一個小動作。
對 Claude Code 的三個預測
以下只是預測。我沒有內幕消息,也不知道 Anthropic 的路線圖。但基於 Anthropic 最近推出的產品,以及 Karpathy 過去幾個月公開發布的內容,方向已經比較清楚。
Anthropic 會構建一個「上下文應用商店」
他們已經開始這麼做了。官方插件、Skills,以及市場化組件的雏形正在形成。
但我說的不是 prompt 市場。
我說的是一類組件:Skills、工作流、專案記憶、垂直領域上下文、評估循環,以及連接真實數據的連接器。還包括那些能教會模型在某個具體崗位裡什麼叫「好」的示例。
你把這些組件接入自己的領域,就能立刻從模型中獲得更高價值,哪怕模型本身已經足夠聰明。
因為對普通用戶來說,模型本身正在變得越來越不再是唯一差異點。真正的問題是:誰能圍繞模型搭建正確的數據和 wrapper,讓它產出真正能為企業帶來 ROI 的結果。
LLM Wiki 是一種將雜亂信息轉化為可用記憶的模式。/Goal 是一種將目標轉化為自動化迴圈的模式。Karpathy 的教育工作,則是一種將複雜 AI 概念變得可用的模式。
他真正包裝的,是一種行為方式。如果 Anthropic 能將這種行為方式變成一個真正的生態,Claude Code 就不再只是一個程式設計工具,而會變成一個市場。
產品裡會出現更多 /goal 風格的命令
/Goal 很可能只是第一個版本,而不是最終形態。
可以想象,未來會出現很多專門版本:研究迴圈、除錯迴圈、結尾迴圈。也可能有針對特定垂直領域優化的命令,在這些場景裡,Agent 已經知道什麼叫「完成」。
我不知道它們最終會叫什麼名字,這不是重點。
重點是互動界面會發生變化。你不再說「做這一步」,而是開始說:「在這個具體垂直場景裡,一直做下去,直到這個條件成立。」
Anthropic 會推出一層教育系統,幫助用戶包裝自己的工作流
這是最大膽的一個預測。老實說,也是我覺得最有趣的一個。
如果 Anthropic 想建立真正的上下文市場,普通人也必須能夠參與貢獻,而不能只面向開發者和研究人員。
也就是說,來自普通職業的領域專家也應該能夠參與進來。
→ 真正理解月度關賬流程的會計。
→ 熟悉房產輸入每一步的地產運營人員。
→ 知道什麼是好包裝、什麼是壞包裝,並能從零開始完成選題頭腦風暴的 YouTuber。
這些知識很有價值。但現在,它們要麼困在人的腦子裡,要麼散落在混亂的文檔、Slack 線程和 ClickUp 頻道裡。
你已經能在現實中看到類似苗頭。很多教練開始搭建自己的 AI 分身和聊天機器人,並向用戶收費,讓用戶與這些 AI 對話。這是手動版。人們想提取他人的專業知識,並把它應用到自己的業務裡。
如果我今天想構建一個廣告 Agent,我會卡住。因為我沒有這個領域的專業知識。但如果有一個市場,能讓我訂閱某個領域高品質的 SME 上下文,我會立即成為客戶。
這就是我接下來會重點關注的一層。
結語
真正的故事,是這個模式本身。
模型只是其中一層。模型外面的 wrapper 正在變成真正的產品。你的數據和工作流,正在變成真正的鎖定效應。Karpathy 過去幾個月一直在教的,正是這件事。Anthropic 過去幾個月一直在做的,也是這件事。
所以,這次加入不是一個新聞標題,而是一張路線圖。我在完整視頻裡拆解了整個邏輯,鏈接放在第一條回覆裡。
[原文連結]
歡迎加入律動 BlockBeats 官方社群:
Telegram 訂閱群:https://t.me/theblockbeats
Telegram 交流群:https://t.me/BlockBeats_App
Twitter 官方帳號:https://twitter.com/BlockBeatsAsia






