

 融資信息
融資信息
 專題
專題
 鏈上生態
鏈上生態
 詞條
詞條
 播客
播客
 活動
活動
 OPRR
OPRR

從可存儲到可結算:Bitroot如何重構AI數據價值層!
文章來源:Bitroot
儲存不是成本中心,是 Bitroot AI Stack 的價值分配系統
很多團隊是在上線大半年後才意識到,儲存這一層當初就該選得更慎重。數據沒丟,服務也沒停,問題卻以另一種方式浮現:歸檔的訓練數據取回越來越慢,熱點向量查詢的尾延遲從毫秒級抖到秒級,等到要複盤一次線上事故,沒人說得清那個模型當時用的是哪一版訓練數據。到這一步,要解決的已經不是擴容,而是三個更難的問題:誰能證明數據一直可用,誰對版本負責,誰為長期成本買單。
把儲存理解成把檔案從中心化雲搬到鏈下網路,在 NFT 元數據時代還能撐住。一旦業務擴展到 AI 訓練語料、模型權重和向量索引,這套思路會迅速失效。
多數團隊至今把儲存當成一筆越省越好的後勤成本,這恰恰是它最被低估、也最容易選錯的地方:在 AI 公鏈裡,它其實是決定誰掌握數據、誰分到收益的價值分配層。這篇文章只回答一個問題:在 AI 與公鏈融合的場景裡,怎樣構建一套可驗證、可治理、可持續的分佈式儲存方案。下文先拆三種主流範式的能力邊界,再講清 AI 數據的特殊難點,最後落到一套五層落地架構和分階段的上線門檻。判斷依據以官方協議文件為主,盡量基於可核驗資料。
以 Bitroot 為例,儲存層更準確的定位是 AI Stack 的價值分配底座。Bitroot 一方面通過並行化 EVM 與 Pipeline BFT 提供高性能鏈上執行環境,另一方面通過分佈式訓練、推理網路、可信執行和 AI 資產管理,把數據、模型、算力和 Agent 應用連接成一個可結算網路。在這個網路裡,儲存不是孤立模塊,而是決定數據能否確權、模型能否複現、算力能否結算、貢獻者能否持續獲得收益的基礎設施。

全上鏈和全中心化,在 AI 場景裡都已經走不通
過去幾年,儲存問題常被簡化成兩選一:要麼全上鏈,要麼全中心化。這兩條路在 AI 場景裡都不可持續。
全上鏈的壓力很具體。訓練數據、模型權重、推理日誌、向量索引普遍是高體量加高頻更新,即便先切片再上鏈,也會同時撞上吞吐天花板和費用曲線。全中心化跑得快,但可驗證性、可追溯性、數據主權和跨主體協作所依賴的信任基礎都很脆弱,一旦涉及多方分帳和確權就站不住。
更關鍵的變化是,AI 把存儲從成本項變成了生產要素。數據版本由誰管理,決定了模型迭代的主動權落在誰手裡;能不能證明數據可用,直接影響算力調度和結算的優先級;而把數據資產化的能力,關係到一個團隊能否在生態裡建立長期激勵。存儲層到這一步已經不再是後勤系統,而是價值分配系統。
所以一套合格的存儲架構,必須同時回答四件事:數據是否真實存在並持續可取,數據與模型的版本關係是否可追踪,權限與收益是否可治理,系統能否在成本和性能之間長期平衡。

Bitroot 的切入點:讓 AI 數據從「可存儲」走向「可結算」
這正是 Bitroot 需要補上的位置。作為面向 AI 場景的高性能 Parallel EVM 公鏈,Bitroot 的存儲叙事不應停留在「數據放在哪裡」,而要回答「數據如何被證明、如何被調用、如何參與分帳」。訓練語料、模型權重、向量索引和推理日誌可以留在更適合大對象的分佈式存儲層,但它們的哈希承諾、版本關係、權限策略、調用記錄和收益事件,需要在 Bitroot 上形成統一的鏈上證據。
從這個角度看,Bitroot 的高吞吐和低延遲不是單純服務 DeFi 交易,而是服務 AI Stack 中更細顆粒度、更高頻的治理事件:數據集更新要錨定,模型版本要註冊,AI Agent 調用要結算,檢索結果爭議要仲裁,存儲節點可用性要被持續挑戰和獎勵。只有底層鏈能承接這些事件,AI 數據資產才不會被鎖在中心化數據庫裡,也不會淪為無法追責的鏈下黑箱。

三種主流範式,沒有一種能單獨打穿全場景
分佈式存儲的競爭,從來不是誰最先進,而是誰在你的數據結構裡最合適。
內容尋址網路解決的是這是不是那份資料,不是誰保證它在線。根據 IPFS 官方文件,CID 是基於內容雜湊的標識,不依賴位置尋址:同一內容在相同編解碼設置下生成同一個 CID,只要內容發生一個位元組的變化,CID 就隨之改變。這個特性讓它天然適合做完整性校驗、去重和跨系統引用,是數據確權的底層能力。但內容尋址不等於經濟上的持久可用,CID 回答的是身份問題,不回答誰來保證它一直在線。很多團隊上線後踩的第一個坑就在這裡:技術上拿到了 CID,業務上卻沒拿到可用性承諾。
存儲市場網路,則是用經濟機制買來了時間維度的可用性。根據 Filecoin 文件,網路通過 Proof-of-Replication 與 Proof-of-Spacetime 建立存儲承諾加持續證明的機制。PoRep 在初始封裝時證明確實存在了這份獨特副本,PoSt 在後續周期裡反覆證明它還在。WindowPoSt 的證明周期通常按 24 小時組織,再切成多個 30 分鐘的證明窗口,存儲方若未在窗口內提交有效證明,就會觸發抵押罰沒和存儲能力下降。在這套體系裡,可用性是持續考核項,不是簽約後的一次性承諾。這種契約化、可稽核的模式適合中長期歸檔、備份和數據市場,但它更像有證明的長期倉儲,不是天然的低延遲在線服務,把高頻在線查詢直接壓上去,體驗會被尾延遲拖垮。
永久存儲網路走的是另一條路,用一次性支付換不可變歷史。根據 Arweave 協議與黃皮書資料,上傳費用的一部分會進入存儲捐贈池 endowment,用於覆蓋長期存儲激勵,把長期可持續性前置進了計費模型,而不是依賴後續的續費習慣。它適合歷史歸檔、關鍵憑證、版權材料這類不可篡改記錄。短板同樣清楚:永久化不自動等於高併發低延遲,實踐中仍要疊加快取、網關或近線索引層,才能滿足用戶側的實時體驗。
除了這三種基礎範式,工程上還有兩種常見組合值得權衡。一種是數據可用性層加對象存儲的混合,數據發布與可用性證明更標準化,代價是跨層協同複雜、介面治理成本高。另一種是多雲加邊緣協同,低延遲和容災更優,但成本治理和一致性管理更難收口。
無論怎麼選,一個協議吃掉所有場景在工程上行不通。有效的方法是按數據類型組合:把持久性、檢索時延、合規拆開,分別匹配能力層,再用鏈上錨定和治理層統一編排。
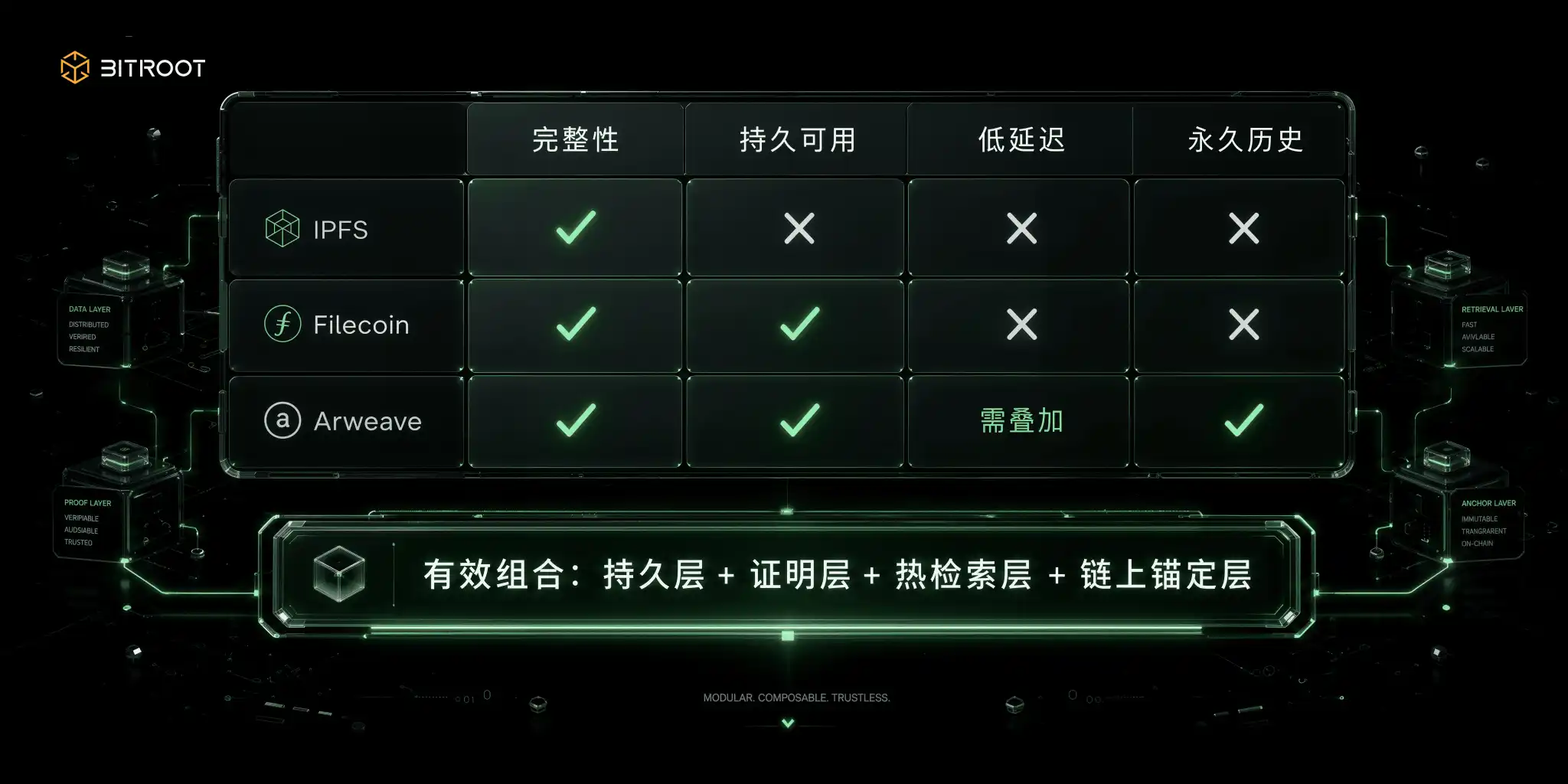
Bitroot 的選擇空間也應當建立在這種組合邏輯上:不是把 IPFS、Filecoin、Arweave 或物件儲存互相替代,而是把它們放進不同職責層。內容尋址用於資料身份和完整性,儲存證明用於長期可用性,永久層用於關鍵歷史和憑證,熱檢索層用於 AI 應用體驗,Bitroot 鏈上層則統一承載版本錨定、權限策略、呼叫結算和爭議處理。換句話說,Bitroot 不需要成為所有資料的物理倉庫,而要成為 AI 資料價值流的可信帳本。
AI 儲存的難點,不在存檔案,而在管生產鏈路
AI 場景下,儲存物件至少分四類:訓練資料、模型權重、向量索引、推理日誌。四類物件的生命週期、存取模式和價值密度完全不同,用一套策略管理,短期省事,長期一定治理失控。
訓練資料的麻煩不在容量,在版本漂移。很多團隊把訓練資料問題等同於 TB 級儲存費用,實際更棘手的是漂移:只要清洗規則、樣本篩選閾值或標註口徑變化,模型行為就會跟著變,而沒有資料版本和模型版本的綁定,離線評估就難以複驗。根據 MLflow 的模型與資料追踪實踐,訓練運行與資料版本綁定是複現實驗的前提。這個原則放到鏈上仍然成立:原始資料不必全部上鏈,但版本承諾、關鍵摘要和來源指紋必須做鏈上錨定。落到工程上至少要綁定三個標識,資料版本、訓練運行、模型版本,缺一個,線上問題回溯就會從查證據退化成猜原因。
模型權重的問題,往往不是能不能下載,而是呼叫邊界誰來管。一個模型進入生產,通常要經歷灰度、主用、回滾、退役幾個狀態,沒有標準化的註冊與授權體系,線上呼叫就是一個不可稽核的黑箱。成熟的模型註冊中心會同時記錄血緣 lineage、版本別名、簽名約束和稽核標籤。對鏈上系統而言,模型版本不該只是一個檔案雜湊,還要和權限策略、收益分配、責任邊界綁在一起。
向量索引的難點集中在一個地方:熱冷分層之後的一致性。向量檢索有個固有矛盾,低延遲和低成本互相打架:熱層要靠記憶體或高性能索引服務保證在線回應,冷層要靠物件儲存壓住長期成本。沒有統一元數據和同步策略,兩層會快速分叉,最終出現同一查詢在不同節點返回不同語義結果的問題。所以向量系統必須支持兩件事,索引建構過程可追踪,熱層索引版本與冷層主數據可核對,這也正是後文可驗證檢索要解決的事。
推理日誌要讓隱私、審計、合規三者同時成立,這很難。它既是安全審計材料,也是隱私風險源:全量明文留存帶來合規風險,完全不留存又失去事故複盤能力。可行做法是三層疊加,內容脫敏後存儲,哈希承諾上鏈,訪問需經審計授權,把不可篡改和可撤銷訪問分層實現。
在 Bitroot 的 AI Stack 中,這四類對象可以對應四種治理動作:訓練數據做版本錨定和來源登記,模型權重做資產註冊和授權調用,向量索引做熱冷分層與一致性證明,推理日誌做脫敏存儲和審計承諾。它們不需要以同一種方式上鏈,但都需要在 Bitroot 上形成統一的資產 ID、版本譜系和調用事件。這樣,數據資產、模型資產和 Agent 應用之間才有可能形成可復用的商業閉環。

可驗證是底線,可用性證明才是分水嶺
沒有可用性證明的存儲承諾,在生產環境裡基本等於沒有承諾。分佈式存儲要進生產,至少要過三道:完整性可證、可用性可證、行為可審計;一旦進入 AI 檢索場景,還要再加最難的一道,檢索可證。
完整性可證靠內容尋址加 Merkle 承諾。內容尋址保證數據指紋穩定,Merkle 承諾保證局部可驗證。工程意義在於,你可以用分片級證明驗證對象的一個子集,而不必每次全量讀取。對大模型權重、大語料和多媒體數據,這一點直接決定驗證成本。
可用性可證靠挑戰機制與抽樣驗證。Filecoin 的實踐已經說明,可用性不是口頭 SLA,而是周期挑戰加鏈上證明,抽象成通用架構就是被動抽查、主動巡檢、失敗懲罰三件套:節點必須在規定窗口響應挑戰,否則觸發扣罰或權重下降。同樣的思路在數據可用性層走得更遠。根據 Celestia 的數據可用性採樣設計,數據從 k×k 擴展到 2k×2k 矩陣,輕節點通過多輪隨機採樣和概率累積,不必下載整塊數據,就能對可用性建立高概率信心。這給 AI 場景一個可遷移的啟發:面對超大對象和高並發訪問,不是所有可用性都要靠全量下載來驗證,統計確認在大規模系統裡更現實。
行為可審計靠鏈上錨定加事件留痕。存儲系統最難管的其實是行為:誰上傳了什麼,誰改了策略,誰觸發了遷移,誰在何時調用了敏感模型。這些行為如果不匯成統一事件流,一旦出現爭議就會回到口說無憑。治理層要做的不是把所有細節搬上鏈,而是在爭議發生時,手裡握著一份最小、確定、可驗證的證據集。
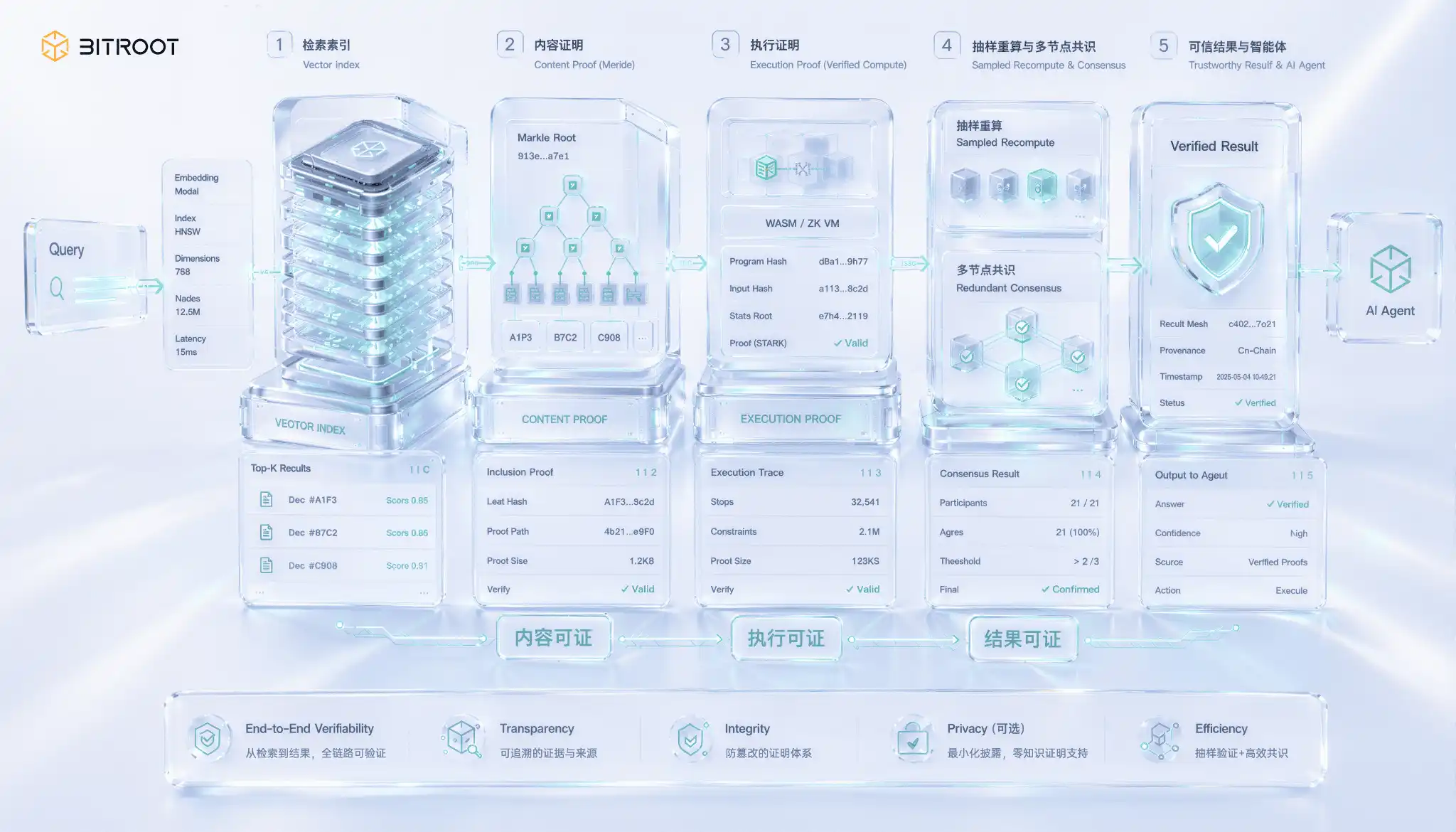
檢索可證是 AI 場景獨有、也最難的一道,問題出在一個容易被忽略的缺口:返回了結果,不等於返回了正確的結果。一個向量檢索節點完全可以拿一份過期索引、甚至跳過真正最近的鄰居,回你一個看起來合理的 top-k,而你單看返回值無從分辨。語義檢索的輸出本身沒有自證性,錯誤不會報錯,只會悄悄拉低召回質量和模型表現。當檢索結果要用於結算、授權或鏈上決策時,這個缺口就從質量問題升級成了信任問題。
把檢索可證拆開,其實是三層逐級變難的保證。第一層是內容可證,證明返回的向量確實屬於某個已承諾的索引版本,做法是對索引建立認證數據結構,用 Merkle 承諾把索引根上鏈,返回結果時附帶包含性證明,確保節點沒有凭空捏造或偷換數據。第二層是執行可證,證明這次查詢確實是在那個已承諾的版本上跑的,而不是在一份私改過的索引上,這需要把查詢過程納入可驗證計算的範疇。第三層最難,是結果可證,證明返回的 top-k 在給定度量下確實是最近的若干個,而不是漏掉了更近的鄰居,這本質上要為近似最近鄰搜索的正確性提供證明。
在生產規模上為高維近似最近鄰做嚴格的結果可證,目前仍是前沿課題,零知識證明等密碼學手段雖在推進,但高維向量運算的證明開銷還遠未到可大規模在線使用的程度。務實的工程解法是分層兜底而非一步到位:先把索引版本和構建參數承諾上鏈,保證可追溯;再對查詢做抽樣重算,按比例抽取在線查詢到可信副本上重跑並比對結果,用統計置信度替代逐條證明;同時讓多個獨立節點冗余檢索、對返回結果取共識,把單點作弊的成本抬高;只有當比對或共識出現分歧時,才升級到對爭議查詢的全量重算與鏈上裁決。這條路線和可用性證明裡抽樣校驗優先的思路一脈相承:大規模系統裡,統計確認加爭議升級,往往比逐條嚴格證明更可落地。
對 Bitroot 而言,可驗證檢索不是一個孤立的存儲功能,而是 AI Agent 可信執行的一部分。一個鏈上 Agent 如果依賴外部知識庫、模型權重或向量索引做決策,系統至少要能回答三件事:它讀取的是哪個數據版本,調用的是哪個模型版本,返回結果是否來自已登記的索引版本。Bitroot 可以把這些證據壓縮成鏈上可驗證事件,讓 Agent 的行為從「看起來智能」進一步變成「可追溯、可爭議、可結算」。

選型的真問題:不是選協議,而是做組合
很多方案評審失敗,是因為問題提錯了。正確的提法不是我們要不要用某協議,而是我們的數據組合是什麼、目標指標是什麼、約束條件是什麼。建議按四個動作走。
先做數據資產盤點。至少區分狀態數據、對象數據、檢索數據、審計數據,把盤點模板做成固定字段,最少八項:數據類型、日增量、峰值並發、讀寫比、保留周期、合規等級、目標時延、成本上限。字段統一之後,跨團隊選型溝通會快很多。
再定義服務等級目標。把 P95/P99 時延、恢復時間 RTO、恢復點 RPO、可用性目標、單 TB 成本上限一一寫死,否則後面所有討論都沒有標尺。
接著建立能力映射。把永久存儲、周期可用性證明、低延遲檢索、訪問治理這幾類能力分別映射到不同技術層,而不是指望單層全包。
最後確定遷移閾值。哪些數據允許過渡期中心化托管,什麼指標觸發遷移,何時必須完成去中心化替換。一個實用做法是預設雙閾值:單 TB 成本連續兩個統計周期超預算,或 P95 時延連續兩周超目標,自動觸發架構遷移評審。沒有閾值就沒有治理,過渡期會變成永久狀態。
落地方案:五層架構,把可存、可取、可管閉成一環
架構的價值不在層數多少,而在能不能形成可驗證閉環。基於前面的框架,方案收斂為五層:鏈上錨定層、對象存儲層、索引檢索層、可用性證明層、密鑰權限層。目標是把可驗證變成默認能力,把高性能變成可配置能力,把治理變成可執行流程。
放到 Bitroot 中,這五層可以進一步理解為一個 AI Stack 的存儲治理模塊:Parallel EVM 提供高頻錨定與結算能力,Pipeline BFT 提供低延遲確定性,分佈式存儲網絡承接大對象與歷史數據,索引檢索層服務 AI Agent 與應用調用,可用性證明層把節點服務質量轉化為信譽與獎勵,密鑰權限層則連接用戶主權、隱私保護和模型商業化授權。
鏈上錨定層只存最小必要狀態:數據承諾、版本指紋、權限策略摘要、結算事件。大對象不上鏈,上鏈的是證明這個對象存在且版本正確的憑據。既保住鏈上可驗證性,又不讓吞吐被大文件拖垮。
在 Bitroot 的架構語境下,鏈上錨定層不只是「記錄哈希」的地方,而是 AI 資產註冊、權限治理、收益分配和爭議裁決的共同入口。資料集、模型權重、向量索引和推理日誌都可以在鏈下按最適合的方式存儲,但它們的版本承諾、授權狀態、調用記錄和收益歸屬需要進入 Bitroot 的鏈上狀態。這樣,鏈下存儲負責承載體量,Bitroot 負責承載信任。
對象存儲層承載真實數據,採用復刪碼加副本的混合策略:高價值、低頻訪問的對象偏重容錯,中價值、高頻訪問的對象偏重檢索效率。這個策略不是靜態配置,要隨訪問熱度和業務等級動態調整。
索引檢索層把元數據索引和向量索引納入統一目錄,熱層承接線上檢索,冷層承接歸檔和重建。所有索引版本都要登記來源數據版本和構建參數,否則索引漂移無法追責。
可用性證明層把節點行為量化。響應挑戰的成功率、響應時延、修復成功率都進入信譽評分,評分再和獎勵分配綁定,避免只獎勵容量、不獎勵可用性。
密鑰權限層控制訪問與合規。高敏數據用分級密鑰和時效授權,推理日誌用脫敏存儲加審計回放,模型調用用可撤銷許可。權限操作本身也要留痕,防止配置漂移。
這五層在執行層面是一個閉環,不是單向流水線:數據接入後先切片編碼進對象層,寫入後生成索引並錨定上鏈;線上查詢走熱層,命中不足回落冷層;返回結果的同時觸發完整性校驗和權限校驗,關鍵行為進入結算和審計。這條鏈路真正的價值在於,任何節點、任何時刻都能回答四個問題:數據從哪裡來,當前版本是什麼,誰有權訪問,系統能不能證明它可用。
這也是 Bitroot 適合承接 AI 存儲治理的關鍵原因。AI Agent 的調用、模型版本的切換、數據授權的變更、檢索結果的爭議,都不是低頻後台操作,而是會隨著應用增長持續發生的鏈上事件。如果底層鏈無法提供足夠低的確認延遲和足夠高的吞吐,存儲治理最終會被迫回到鏈下表格和人工對賬。Bitroot 的 Parallel EVM 與 Pipeline BFT 組合,價值不只是更高 TPS,而是讓這些高頻治理事件可以被實時錨定、結算和追責。

誰來埋單:讓可用性而非容量決定收益
存儲要長期跑得動,激勵必須對準可用性,而不是堆容量。只獎勵容量,等於變相鼓勵節點堆硬盤、輕服務。這一點 Filecoin 已經用機制做過修正:它引入了質量調整算力 quality-adjusted power 的概念,讓承接了真實存儲訂單、尤其是經過驗證的有效訂單的扇區,也就是存儲空間的最小計量單元,在算力計量上獲得更高權重,從而把獎勵向真正提供服務的容量傾斜,而不是向單純封裝的空容量傾斜。這個思路值得任何自建激勵層借鑑。
把它落成一個可執行的獎勵函數,至少要把四個維度同時計入,並明確各自的權重邏輯。容量決定基礎份額,回答你承諾了多大空間。在線率和響應時延決定服務質量係數,回答這塊空間在被需要時是否真的可取,這一項應當占較高權重,否則可用性就淪為口號。數據恢復成功率決定容災可信度,回答節點掉線後副本能否被重建,它直接關係長尾數據的存活。數據價值密度決定需求側加成,對高價值數據集和高需求模型設置差異化倍率,讓稀缺且被頻繁調用的數據獲得更高回報。獎勵應該發給可被證明的服務,而不是被聲明的容量。
光有正向激勵不夠,約束側的質押、懲罰、仲裁要同時到位,而且得滿足一個底層不等式:作弊的預期收益必須低於被罰沒的預期成本,否則任何證明機制都會被經濟理性繞過。質押讓節點為可用性承諾押上成本,抵押規模應與其承諾的算力和數據價值成正比;Filecoin 的設計裏,存儲方需要按承諾算力繳納前置抵押,一旦在證明窗口內掉線就觸發故障費,扇區被永久放棄則觸發更重的終止罰沒,這套階梯式懲罰的意義在於把短期掉線和惡意退出區別對待。仲裁則用鏈上證據驅動爭議處理:當用戶主張數據不可用、節點主張已正常服務時,挑戰記錄、採樣證明和事件日誌構成可機讀的裁決依據,把原本需要人工介入的爭議壓縮成一次可驗證的鏈上判定。
AI 場景還要在這之上疊一層更難的治理:三方收益怎麼拆。一份被反復調用的模型,背後是數據貢獻者提供的語料、模型貢獻者投入的訓練、存儲節點承擔的托管,三方都對最終的調用價值有貢獻,但貢獻難以直接觀測。可行的做法是把價值歸因建立在可計量的鏈上事件上:調用按次計費並自動結算,數據與模型通過版本指紋和血緣關係綁定到每一次調用,再按預先寫死的可編程分帳比例自動拆分,避免事後扯皮。與之配套的是黑名單與罰沒機制,對惡意數據上傳、版權侵權、模型盜用這類行為,一旦經仲裁認定即扣押抵押並凍結後續收益。否則會出現一個反直覺的結果:資產化越成功,分帳和確權的爭議越多,最終拖垮的恰恰是生態信任本身。
合規不是上線後的補丁,而是架構期的約束:安全基線是端到端加密、分層金鑰管理和周期輪換,疊加雜湊驗證與 Merkle 承諾保證下載可驗證,再用多副本和純刪碼聯合容災兜住故障恢復;隱私側按數據等級做最小權限訪問控制,支持可撤銷授權、一次性授權和時效授權,關鍵訪問與操作全鏈路留痕,便於審計回放。合規也是最容易被後置、代價最高的一環:數據本地化和跨域傳輸策略要可配置,刪除、訪問、審計請求要有標準流程接口;最棘手的是不可篡改與可刪除的天然衝突,可行解法是加密擦除加索引失效:銷毀金鑰讓密文不可還原,讓索引失效讓數據無法被檢索,在保留鏈上記錄的前提下滿足刪除訴求。從試點到生產有三道階段門檻:先建立最小可信閉環,把對象存儲、鏈上錨定、完整性校驗和基礎監控跑穩,驗收看可用性、讀寫成功率、錨定與對象版本一致率、故障恢復可演練;再做 AI 資產化與索引治理,引入數據集與模型資產管理、版本譜系、向量索引熱冷分層、模型授權呼叫和訓練數據來源登記,驗收看訓練可追溯、模型可回滾可審計、熱層時延達標、索引重建影響可控;最後上可驗證檢索與自動化治理,引入挑戰證明、策略遷移和獎懲自動化,驗收看可用性證明覆蓋率、風險處置時延、單位成本下降、策略變更可追蹤可回滾。指標體系是策略系統而非展示報表。若只寫技術項目、不寫業務結果,存儲方案會塌成純成本中心;建議分三層:基礦技術指標(可用性、P95/P99 時延、吞吐、RTO/RPO、錯誤率)回答系統是否健康,AI 專項指標(訓練數據可追溯率、模型可復現率、推理驗證覆蓋率、索引一致性)回答模型質量是否可治理,業務結果指標(數據供給增長、呼叫成本下降、節點活躍度、資產交易規模)回答系統是否創造價值,三層之間要有映射關係,指標真正的用途是策略調優的輸入,而不是展示用的報表。最常見的五個失敗點基本都能提前規避:只做存儲不做版本治理,數據在不代表可用、可用也不代表可復現;只看容量不看可用性證明,獎勵按容量發會誘導堆容量輕服務;熱冷分層做了但同步策略沒做,索引版本同步與失效處理未閉環;合規策略後置,權限、日誌、脫敏、刪除響應越晚補代價越大;過渡架構沒有退出機制,先中心化後去中心化是合理路徑,但缺遷移閾值會讓過渡態固化、背離初衷。
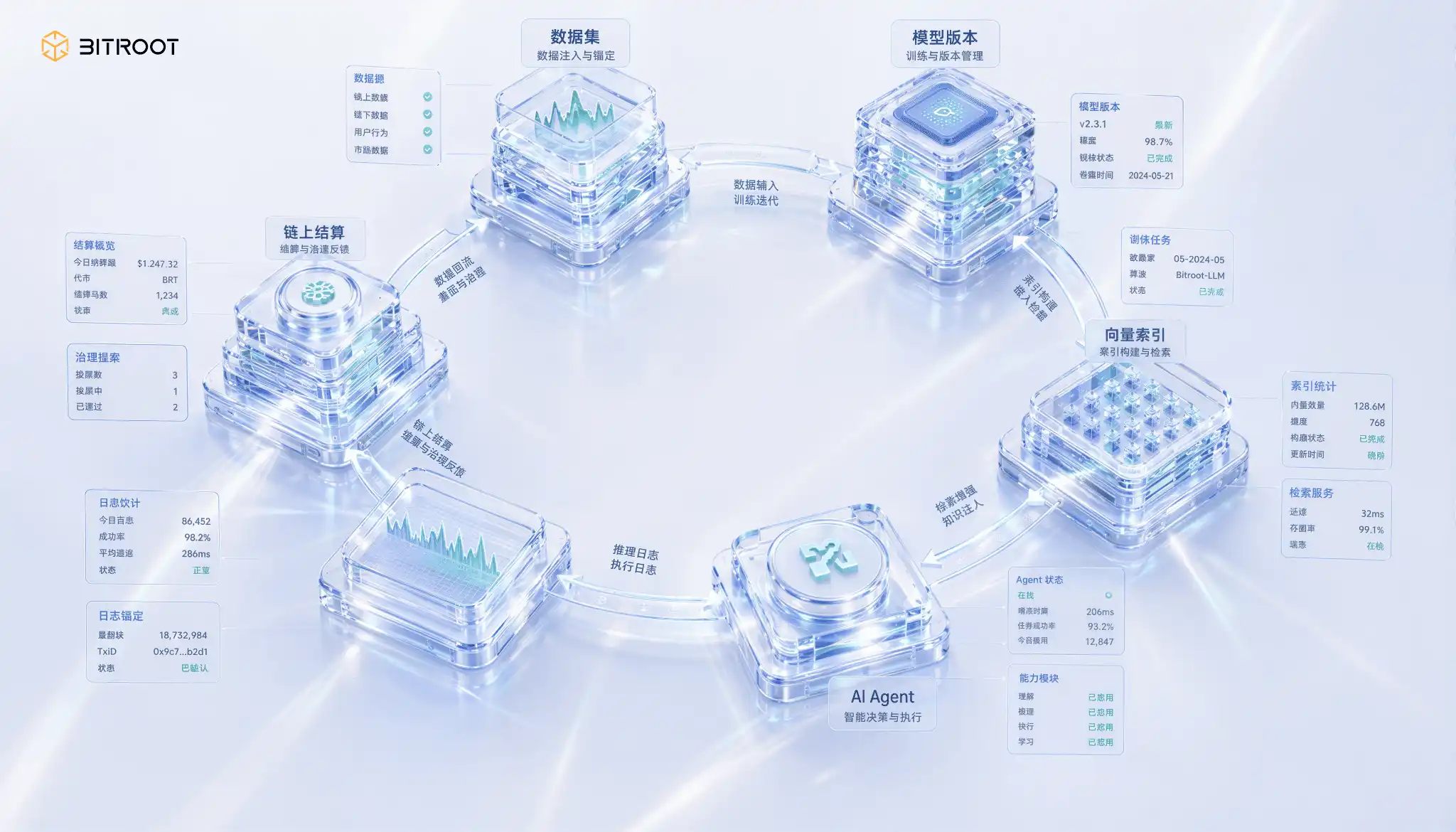
Bitroot 的完整閉環:從數據、模型到 AI Agent
在這個閉環裡,Bitroot 可以將 AI 資產的每一次關鍵行為都轉化為可結算事件:數據集註冊、模型版本發布、向量索引重建、AI Agent 調用、推理日誌錨定、權限授權與撤銷、爭議挑戰與仲裁結果。鏈上不需要承載全部數據,卻必須承載這些行為的最小證據。只有這樣,數據、模型、算力和應用之間的價值關係才不會停留在口頭承諾,而會進入可編程分帳和可稽核治理。
把這套機制放到 Bitroot 的運營和生態擴張裡,存儲激勵不應被設計成單獨的硬件補貼,而應成為 AI Stack 價值流的一部分:數據貢獻者因數據被訓練或調用獲得收益,模型貢獻者因模型服務獲得收益,存儲與檢索節點因持續可用和低延遲服務獲得收益,驗證與挑戰節點因發現不可用、索引漂移或權限異常獲得獎勵。這樣,Bitroot 的經濟系統獎勵的不是「上傳過」,而是「持續可證明地有用」。
存儲不是成本中心,而是信任與價值分配系統
分佈式存儲在 AI 時代要解決的,不是替換某個對象存儲產品,也不是追求一個去中心化敘事,而是四件更硬的事:長期可用的可信證明,跨主體協作的治理秩序,數據與模型的責任鏈路,可持續的經濟激勵。
單協議單層架構覆蓋不了這些目標。更現實的路徑是組合式架構:內容尋址保完整性,存儲證明保時間維度的可用性,永久層保關鍵歷史,熱層保在線體驗,鏈上錨定保治理與結算可證。這不是妥協,是工程理性。落地的重點也不在功能最全,而在閉環最先成立,先把最小可信閉環跑通,再把 AI 資產化、可驗證檢索和自動化治理逐層疊加。
把這套方法壓縮成一周的行動,其實只有三步:第一天完成一張八字段的數據盤點表,第三天在一個真實業務域跑通一次從接入、存儲、檢索到驗證的最小鏈路,第七天用 P95 時延和單位成本開一次遷移閾值複盤會。做到這三步,團隊就從概念共識進入了工程共識。
也要承認一個現實邊界:無論採用哪種協議組合,成本、時延、持久性之間都存在取捨,不存在對所有業務同時最優的單一答案。真正可持續的方案來自清晰邊界下的持續迭代,而不是一次拍板後的長期靜態配置。
未來淘汰一個專案的,往往不是 TPS 不夠高,而是數據責任鏈說不清;在 AI 公鏈時代,存儲不是把數據放進去,而是讓數據在任何時刻都能被證明。
結語
真正的 AI 公鏈競爭,最後不會只停留在 TPS、Gas 或確認時間的對比上。性能是入口,但不是終局。進入 AI 原生應用時代後,鏈上系統要承載的不只是交易,還包括數據版本、模型調用、算力調度、推理記錄、Agent 行為和多方收益分配。
這也是 Bitroot 對存儲層的判斷:存儲不是一個附屬模塊,而是 AI Stack 中最接近價值源頭的一層。數據能不能被證明,模型能不能被複現,調用能不能被審計,收益能不能被自動分配,決定了一個去中心化 AI 網絡是否真正具備長期生命力。
Bitroot 要構建的,不是一條只追求更快執行的鏈,而是一套讓 AI 資產能夠被確認、被調用、被結算、被治理的基礎設施。Parallel EVM 和 Pipeline BFT 解決的是高頻鏈上事件的承載能力,分佈式存儲與可驗證機制解決的是 AI 數據和模型的信任基礎,而可編程分賬與鏈上治理,則把貢獻轉化為持續的經濟激勵。
當 AI Agent 開始代表用戶行動,當模型和數據開始成為可流通資產,當算力、存儲和推理服務進入同一個價值網絡,存儲就不再是「把文件放在哪裡」的問題。
它會成為 AI 公鏈的信任底座,也會成為下一代智能網絡的價值分配系統。
在 Bitroot 看來,未來真正重要的不是誰擁有最多數據,而是誰能讓數據在任何時刻都可證明、可調用、可追責,並最終參與價值結算。
關於 Bitroot
Bitroot 是一個聚焦並行執行與 AI 原生架構的 Layer 1 公鏈專案。Bitroot 採用 EVM 兼容技術路線,並通過並行執行機制、共識優化和 AI 相關接口設計,探索為 AI Agent、DeFi 及 Web3 應用提供高性能、低成本的鏈上執行環境。
本文來自投稿,不代表BlcokBeats觀點。
歡迎加入律動 BlockBeats 官方社群:
Telegram 訂閱群:https://t.me/theblockbeats
Telegram 交流群:https://t.me/BlockBeats_App
Twitter 官方帳號:https://twitter.com/BlockBeatsAsia






