

 融資信息
融資信息
 專題
專題
 鏈上生態
鏈上生態
 詞條
詞條
 播客
播客
 活動
活動
 OPRR
OPRR

DeepSeek的十萬億美元之路:用開源撬動兆級硬體生態
原文標題:DeepSeek 的 10 兆美元宏偉戰略
原文作者:@bookwormengr
編譯:Peggy,BlockBeats
編者按:過去一年,圍繞 DeepSeek 的討論大多集中在模型表現、開源策略和價格戰上。但如果只從「賣不賣訂閱」「有沒有多模態」「能不能做 coding agent」來理解 DeepSeek,可能低估了它真正想改變的東西。
這篇文章提出了一個更激進的判斷:DeepSeek 的目標未必是短期通過應用層變現,而是通過一系列底層架構創新,重塑 AI 訓練與推理的成本結構,並間接推動一個新的硬件生態形成。從 MoE、MLA 到 DSA、CSA、mHC、Engram,再到 Dual Path 和 TileLang,DeepSeek 的技術路線始終圍繞一個核心問題展開:在 HBM、先進製程、封裝和 CUDA 生態都受限的情況下,如何用更少的高端算力跑出更強的模型。
文章最值得關注的,不是「DeepSeek 是否能靠 API 或訂閱賺到幾億美元」,而是它是否正在把模型能力、內存體系和國產硬件生態綁定到一起。KV Cache 壓縮降低了對 HBM 的依賴,NAND 和 SSD 可以承接長時間緩存,LPDDR 可以用於權重流式加載和 Engram 存儲,TileLang 則試圖削弱 CUDA 護城河。這些創新如果持續擴散,受益者就不只是 DeepSeek 本身,還包括存儲、ASIC、GPU、網路晶片以及整個 AI 基礎設施鏈條。
當然,文中關於「10 萬億美元產業生態」和「1 萬億美元估值」的判斷,仍帶有較強推演色彩。但它提供了一條理解 DeepSeek 的重要路徑:開源並不一定意味著放棄商業化,低價也不一定只是補貼市場。對 DeepSeek 來說,真正的生意可能不在應用層,而在幫助更多硬件變得可用、讓更低成本的 AI 供給成為可能。換句話說,它賣的未必是模型本身,而是下一代 AI 基礎設施的可行性。
以下為原文:

你有沒有想過,DeepSeek 到底要怎麼賺錢,而且可能賺很多錢?
它沒有像 GLM、MoonShot 和 MiniMax 那樣推出具競爭力的程式訂閱方案;也沒有多模態、音訊、影片模型。到目前為止,它甚至還沒有自己的 harness,也就是用於模型呼叫、工具接入和任務執行的外層執行框架——雖然他們最近已經開始招聘相關職位,準備搭建這一體系。
與此同時,DeepSeek 似乎還長期堅定地站在開源一邊,甚至很樂意公開分享自己的「秘訣」。這難道不是瘋狂嗎?不是在白白燒錢嗎?那些準備向它投資 100 億美元的投資人,難道是在把錢扔進下水道嗎?
我個人認為,答案恰恰相反。
接下來,我會基於 DeepSeek 迄今為止已經做過的事情,提出一些觀察,並分析它似乎正在遵循的一套戰略。DeepSeek CEO 梁文鋒的目標,可能遠不止眼前的模型競爭。他瞄準的或許是一個更大的獎項:DeepSeek 有機會衝擊 1 萬億美元估值,同時推動一個規模達 10 萬億美元的新產業形成。

TechInAsia 關於 DeepSeek 最新一輪融資的報導
重訪 DeepSeek 的「英雄之旅」
DeepSeek 一直在逆風而行。它沒有選擇不斷推出稍微更強一點的模型,然後急於把它們包裝成可直接變現的應用,比如程式訂閱方案。2025 年 1 月 27 日,我曾發過一條傳播很廣的推文,講述我眼中 DeepSeek 的「英雄之旅」。如今,這個故事變得更加有趣了。
當其他人還在嘗試構建密集模型時,DeepSeek 選擇了更難訓練的專家混合模型(Mixture of Experts,MoE)。
他們採用「第一性原理」的方法,發明了新的 GRPO 算法,用來替代當時主流但實現成本更高的 PPO 強化學習算法。
他們發現,基於可驗證獎勵的強化學習(Reinforcement Learning from Verified Rewards,RLVR),是提升模型推理能力的關鍵策略。
他們還通過「多 Token 預測」(Multi Token Prediction)提出了一種簡單的推測解碼策略,同時也讓訓練信號變得更加密集。
他們完善了「零氣泡」(ZERO bubble)流水線,以提高有限 GPU 資源的利用效率。
他們發布了專家負載均衡器,使所有人都能更容易地部署 MoE 模型。尤其是通過「寬專家並行」(Wide Expert Parallel)策略,模型可以以更大的 batch 進行服務,從而大幅降低推論成本。
他們發明了 MLA、DSA、CSA、HCA 等機制,用於減少 KV Cache 的需求,並讓隨著上下文長度增長而增加的計算需求盡可能保持接近恆定。
他們發明了 Engram,用內存換取計算效率。
他們還發明了 mHC,使模型規模擴大時依然能夠實現穩定訓練。類似的例子還有很多。
在「英雄之旅」這一最普遍的敘事結構中,英雄從來不會一開始就決定自己的旅程究竟通向哪裡。他是在一路學習中,逐漸發現自己真正偉大的使命,並在重重阻礙之下完成它。他會遇到許多質疑者,但他選擇無視他們。他也會遇到許多惡意行動者。他有明顯的缺陷或短板,但最終會克服這些問題,完成自己的使命。他面對看似無法跨越的挑戰,卻能找到結盟的方法,並學會如何明智地使用有限而珍貴的資源。正是這一點,讓觀眾願意為英雄加油。這也是 DeepSeek 贏得追隨者、全球尊重以及反對者的原因。
正如我接下來會詳細說明的,DeepSeek 已經在這條路上走了很久,並且逐漸發現了自己的終極命運:它的目標不是出售編程訂閱方案,而是推動一個規模達 10 萬億美元的中國 AI 硬件生態,並讓自身實現 1 萬億美元估值。在這個過程中,它也將為西方硬件生態中的許多新進入者創造機會。

先從一些有趣的 KV Cache 計算開始
請看 @SemiAnalysis_ 最近這條很及時的推文:
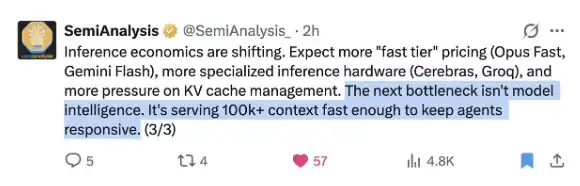
DeepSeek 已經比任何人都更好地解決了這個問題!
我們先來做一點有趣的 KV Cache 計算。別擔心,就算你不喜歡數學也沒關係。我們會使用最近發布的 KV Cache 計算器,來看看 DeepSeek V4 Pro 能帶來多少 KV Cache 節省,並將它與最新的 GLM 和 Qwen 模型進行對比。
這裡我以 100 萬上下文長度進行計算,假設 KV 精度為 8 位,索引器精度為 16 位。你也可以自己打開這個計算器試一試:https://kvcache.ai/tools/kv-cache-calculator/
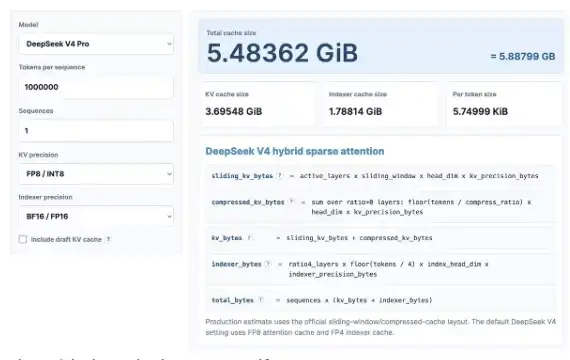
你也可以自己打開計算器試試看!
在 100 萬上下文長度下:
·DeepSeek V4 只需要 5.48GB HBM;
·GLM-5 需要 60GB HBM;
·Qwen3-235B-A22B 則需要高達 89GB HBM。
要注意的是:
·DeepSeek 是一個 1.6 萬億參數模型;
·GLM-5 大約是 7000 億參數,並且已經採用了 DeepSeek 的 MLA 和 DSA,不過還沒有使用最新的壓縮注意力機制;
·Qwen3-235B-A22B 大約是 2350 億參數,採用的是 GQA 注意力機制。
DeepSeek 在緩解內存壓力方面,已經做出了基礎性貢獻。如果這類創新被廣泛採用,將大幅降低長周期 Agent 的運行成本,並解鎖下一批新的應用場景。
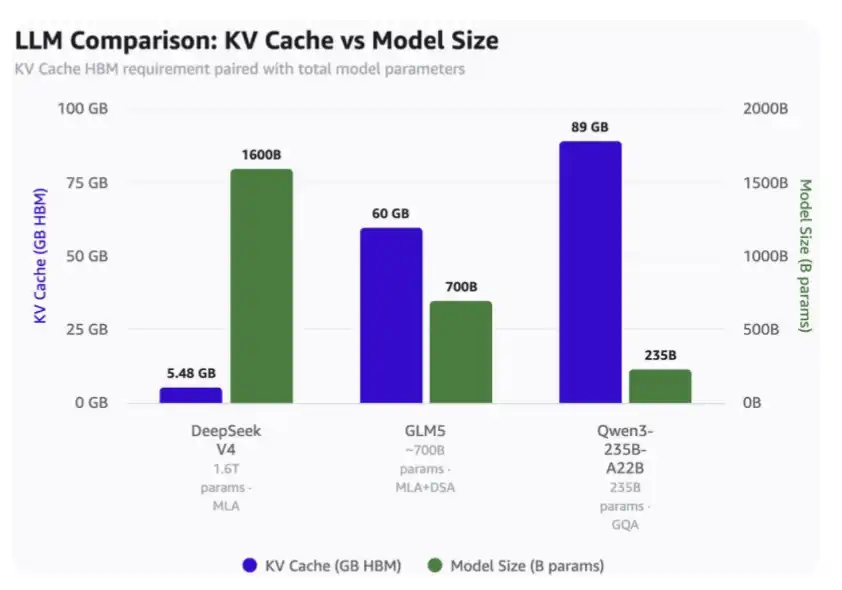
100 萬 Token 上下文與模型規模下的 KV Cache 佔用對比
「瘋狂」背後的方法論
KV Cache 體積之所以能做到這麼小,同時又不犧牲模型質量,正是 DeepSeek 能夠以極低價格提供長時間緩存的原因——其價格甚至不到 Sonnet 4.6 緩存命中價格的 3%,而且 DeepSeek 可以將緩存保留數小時。
對於長周期任務來說,較小的 KV Cache 意味著可以更經濟地將其卸載到 SSD 中,並在需要時重新加載。這樣一來,就能減少對 HBM 的依賴。站在中國 AI 硬體產業的角度看,HBM 不僅供應緊張,也是最難製造的記憶體類型之一。
此外,DeepSeek 還開發了從 SSD 更快加載 KV Cache 的技術,這一點在其 Dual Path 論文中已有描述。
DeepSeek V4 對 KV Cache 的壓縮幅度非常大,以至於這一步甚至可能都不再必要。
那麼,KV Cache 壓縮最直接的受益者是誰?
誰在大規模供應 SSD?別忘了,YMTC(長江存儲)正在成長為 3D NAND 領域的巨頭。NAND 可以幫助 DeepSeek 避免重複計算 KV。反過來,DeepSeek 也為 NAND 和 SSD 創造了一個巨大的市場——這不僅會讓長江存儲受益,也會讓其他相關廠商受益。

不過,這不僅僅關乎 NAND 和 SSD。
LPDDR 記憶同樣有巨大潛力。它可以作為存放模型權重的地方,並在需要時將這些權重流式傳輸到 HBM 中,從而緩解對 HBM 的需求壓力。SGLang 團隊曾發布過一篇很好的部落格對此進行介紹。下面這張圖展示了這一方案的工作原理。
雖然 DeepSeek 並沒有專門為這一方案做什麼特定設計,但它的 MoE 架構、本身擁有大量專家模型,以及 4 bit 權重的特性,都讓這一方案更容易落地。
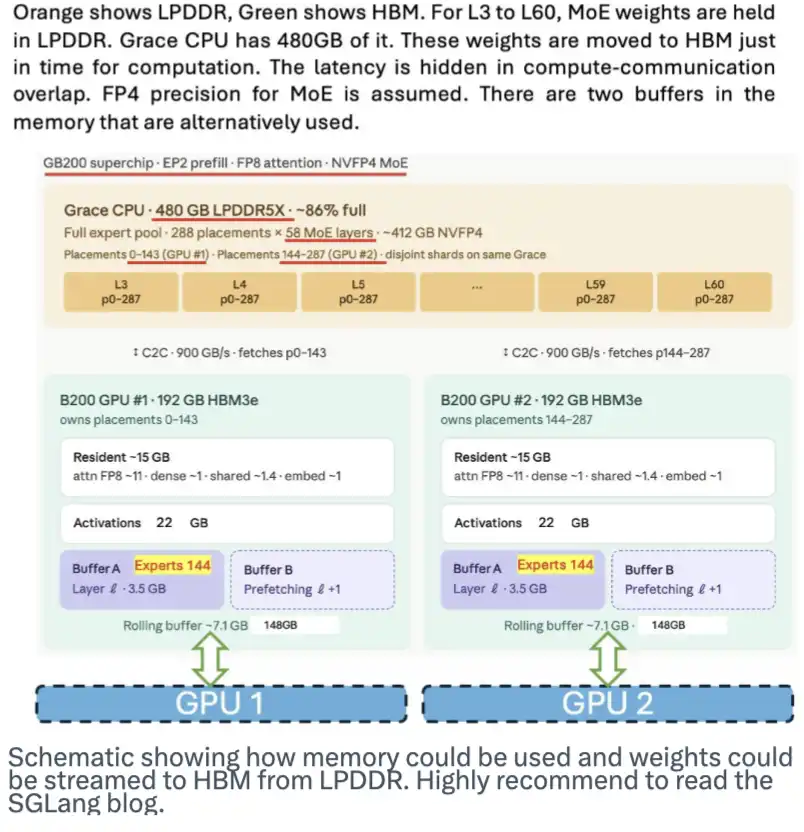
這張示意圖展示了記憶可能如何被使用,以及模型權重如何從 LPDDR 流式傳輸到 HBM 中。強烈推薦大家閱讀 SGLang 的那篇部落格。
這項創新如果與極其緊湊、且無損的 KV Cache 結合起來,將顯著降低對 HBM 的需求。
那麼,中國誰在生產 LPDDR?答案是 CXMT,也就是長鑫存儲。它們在 LPDDR 速度上只落後約半代,在密度上落後一代,差距並不算大。
除了充足的 NAND 之外,中國 AI 生態在不久的將來,也將擁有充足的 LPDDR 供給。這能緩解算力壓力嗎?答案是:可以。繼續往下看。

智能使用內存,同樣可以減輕 GPU / ASIC 的壓力
使用 NAND 來存放 KV Cache 的作用其實很容易理解:它可以讓 KV Cache 保留更長時間,降低對 HBM 的壓力,同時避免重複計算 KV Cache,從而減輕 GPU 和 ASIC 的計算負擔。
那麼,LPDDR 是否也能以類似方式發揮作用?除了作為一個可以「按需即時」將權重流式傳輸到 HBM 的存儲位置之外,它還能進一步降低計算壓力嗎?
答案是:可以。
LPDDR 可以用來存放大量被稱為 Engram 的內容。在 DeepSeek 的 Engram 論文中,他們指出,MoE 可以通過條件計算來擴展模型容量,但 Transformer 本身缺少一種原生的「知識查找」機制。因此,Transformer 往往不得不通過計算來低效地模擬檢索過程。
為了解決這個問題,DeepSeek 提出了 Engram 模塊。它將經典的 N-gram embedding 現代化,改造成一種基於哈希的 O(1) 查找機制,從而創造出一條互補的稀疏化路徑,他們稱之為 條件記憶(conditional memory)。
這種方式可以節省計算,但也需要內存來承載 embedding table,而這個表本身可能非常龐大。
本質上,這是一種典型的「以內存換計算」的方案。但其關鍵洞察在於:從每 bit 數據讀取成本來看,「內存」這一側要便宜得多——一次 LPDDR 查找,遠比讓數據完整經過多層 Transformer 做一次前向計算便宜。因此,在大規模場景下,這是一筆非常划算的交換。
這就是 DeepSeek 通過犧牲部分內存、換取計算節省的方式。
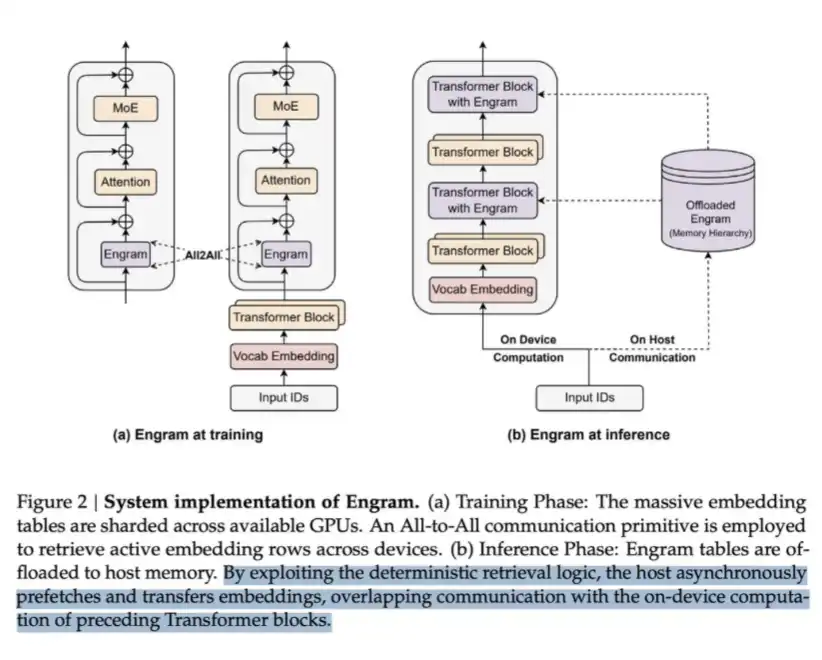
值得做出的取捨
由於沒有同等水準的晶片晶體管密度,也沒有 EUV,中國 GPU 和 ASIC 在原始 FLOPs 計算能力上,很可能長期落後於西方 GPU。它們在先進封裝方面也仍有明顯差距。因此,這類取捨非常值得做,尤其是在中國能夠大量生產 NAND 和 LPDDR 記憶體的前提下。
回顧 DeepSeek 的長期戰略
從這些創新來看,DeepSeek 的目標似乎並不是眼下賺幾億美元利潤。它過去做出的很多選擇都說明了這一點:到現在還沒有多模態,沒有語音模型,視頻模型更是談不上。
它真正參與的,是一場耐心的、規模可能達到 10 萬億美元 的長期遊戲:推動一個替代性 AI 硬件生態的形成。
這不僅是為了讓中國記憶體廠商在中國乃至全球 AI 硬件市場中成為關鍵玩家,更是為了從根本上降低資源需求,讓 AI 模型的訓練和服務變得更具成本效率。這樣一來,許多 GPU、ASIC 廠商,以及網路晶片廠商,都有機會成為可行選項。
與此同時,這些創新也將惠及西方開源生態,以及新一代硬件製造商。
所有跡象其實都已經出現了。我們不妨詳細回顧一下 DeepSeek 至今提出的這些創新:
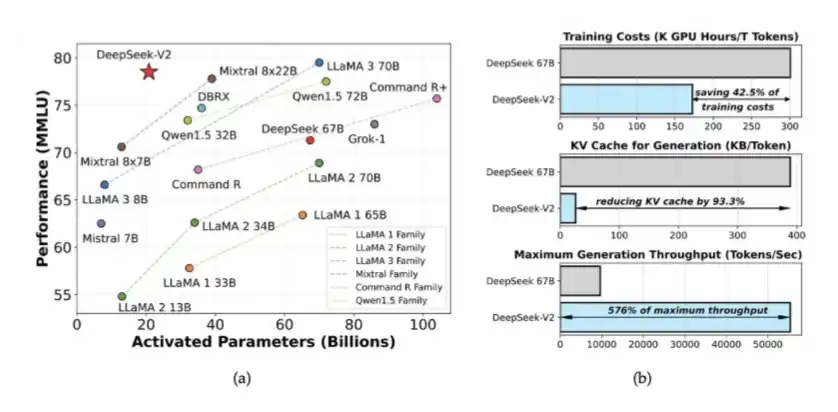
1、DeepSeek V2 中引入的專家混合模型(MoE)和 MLA
DeepSeek 在 V2 中引入了 MoE 和 MLA。MoE 讓訓練高智能模型所需的計算量減少了約 40% 到 50%;MLA 則使 KV Cache 減少了 90%。
這讓將 KV Cache 卸載到 SSD 上變得相當高效。
這些想法最早出現在 DeepSeek 於 2024 年 5 月發布的 DeepSeek V2 論文中。後來,它們也為 DeepSeek V3 的訓練奠定了基礎。當時,DeepSeek 僅使用 2048 張被削弱性能的 H800 GPU,就訓練出了一個性能接近閉源模型水準的系統。
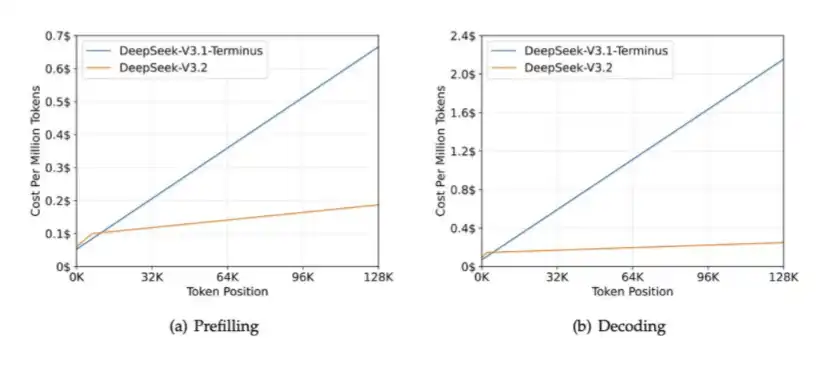
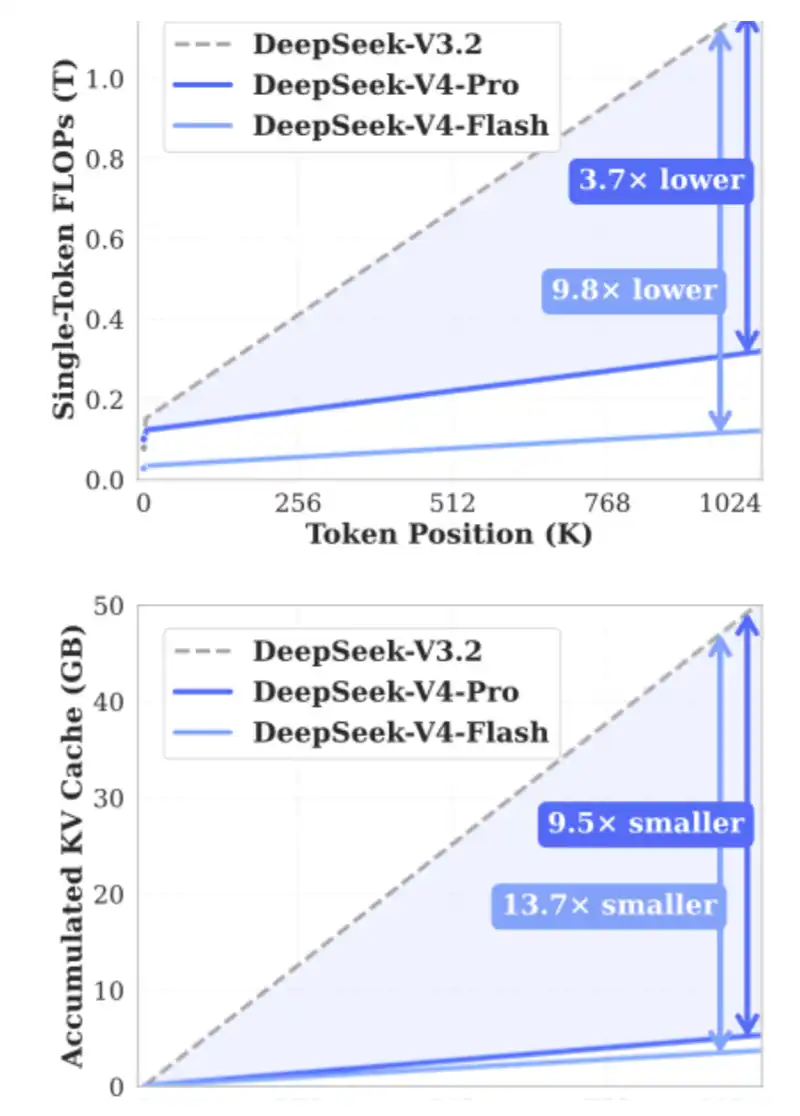
2、DSA:在 DeepSeek V3.2 Exp 中引入,用於降低長上下文情境下的計算開銷,同時緩解 HBM 寬頻壓力。
DSA 的核心作用,是確保計算量不會隨著上下文長度的增加而持續增長。可以看下面的圖表:隨著上下文長度增加,DeepSeek-V3.2 的處理時間基本保持平穩。
3、mHC:DeepSeek 於 2025 年 12 月在論文《mHC: Manifold-Constrained Hyper-Connections》中提出。
mHC 是 DeepSeek 在宏觀架構層面的一項創新,它重新設計了 Transformer 層之間的資訊流動方式。
過去,從 ResNet 以來,模型通常使用標準殘差連接,也就是 x + F(x)。而 mHC 的做法,是把殘差流擴展成多條並行的資訊通道,並允許模型在這些通道之間進行可學習的混合。關鍵在於,它會將混合矩陣約束為雙隨機矩陣,也就是通過 Sinkhorn-Knopp 投影將其限制在 Birkhoff 多面體上。這樣一來,從數學上可以保證,無論模型堆疊到多深,信號幅度都能保持穩定。
這解決了此前無約束 Hyper-Connections 所面臨的災難性不穩定問題。Hyper-Connections 最初由字節跳動提出,但在沒有約束的情況下,信號放大會在 270 億參數規模上暴漲至 3000 倍,最終導致訓練完全崩潰。
mHC 的計算成本很低:它只帶來約 6.7% 的實際訓練耗時開銷,因為它並沒有改變注意力層或 FFN 層的 FLOPs,只是改變了這些層的輸出在層間的路由方式。
但它帶來的性能提升相當明顯:在 270 億參數規模下,mHC 在 BIG-Bench Hard 推理任務上提升 7.2 分,在 DROP 上提升 3.2 分,在 GSM8K 數學任務上提升 2.8 分,在 MMLU 通用知識任務上提升 1.4 分。而這些提升都是在相同模型規模、幾乎相同計算預算下實現的。
本質上,mHC 是通過為網路提供一種更豐富、更具表達能力的跨層資訊路由拓撲,在幾乎不增加額外 FLOPs 的情況下,實現了更高的單位參數智能。
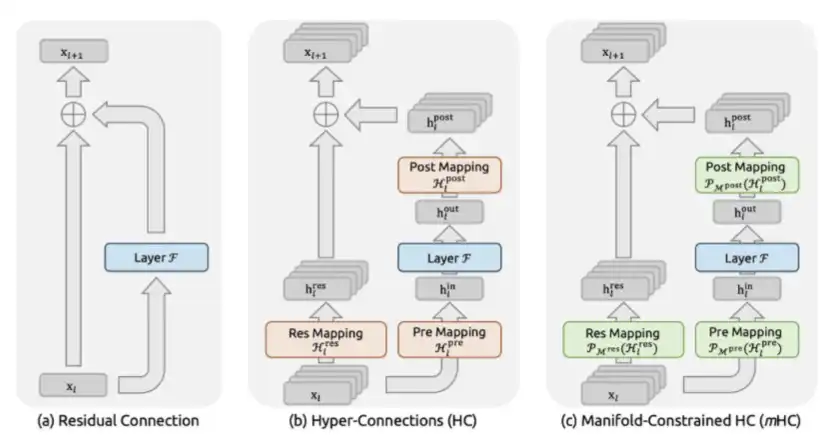
mHC 是一種複雜的架構設計,但它能夠帶來更穩定的訓練過程,以及更高的單位參數智能。
4、CSA、HSA:DeepSeek 於 2026 年 4 月在 V4 中引入。
CSA 和 HSA 的目標,是通過壓縮 KV Token,將 KV Cache 需求再降低 90%,同時大幅減少所需 FLOPs,從而同時緩解 HBM 以及 GPU / ASIC 的壓力。
5、Engram:DeepSeek 於 2026 年第一季度引入,本質上是在某種程度上用內存,也就是 LPDDR 內存,來換取計算效率。
如下方這張詳細圖表所示,在總參數預算相同的情況下,Engram 帶來了明顯的性能提升。
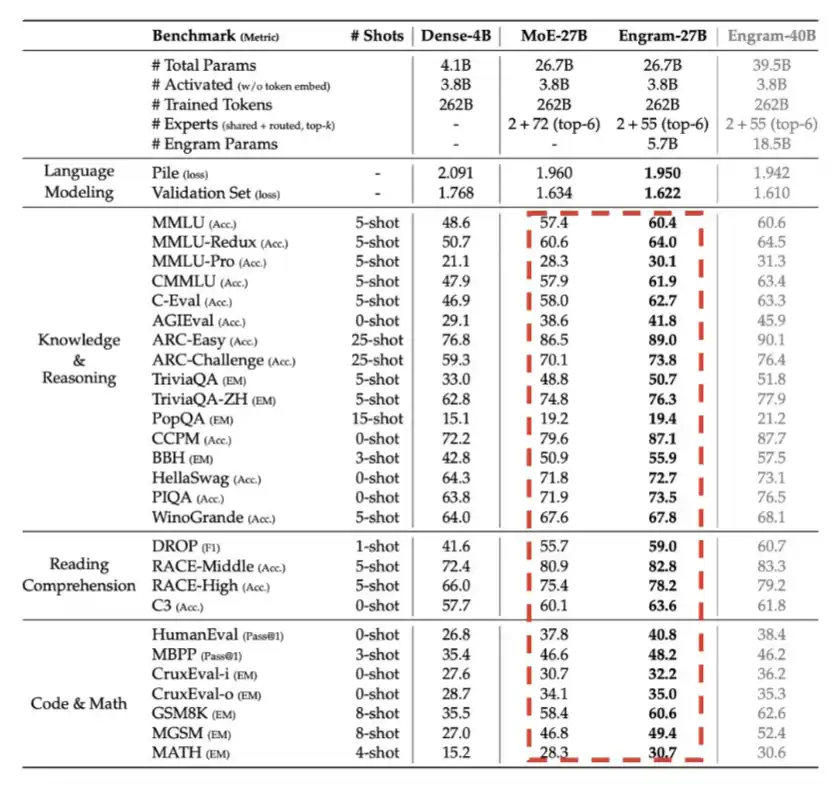
6、Engram:DeepSeek 於 2026 年第一季度引入,本質上是在某種程度上用內存,也就是 LPDDR 內存,來換取計算效率。
如下方這張詳細圖表所示,在總參數預算相同的情況下,Engram 帶來了明顯的性能提升。

這是 DeepSeek 在 V4 論文中分享給硬件廠商的建議。我很確定,在線下交流中,他們給出的反饋只會更多。
7、對 TileLang 的投入,也指向了同一個方向:DeepSeek 不是只在解決自己的算力瓶頸,而是在推動中國硬件生態具備與西方生態競爭的能力。
借助 TileLang,開發者可以只編寫一次 kernel,也就是用於計算的底層代碼,然後讓它在多個硬件平台上成功運行,前提是這些平台已有對應的 TileLang 後端支持。
我預計,其他中國 AI 實驗室也會陸續加入進來。這將幫助中國硬件廠商以一種間接方式應對所謂的「CUDA 護城河」。同時,它也會釋放更多西方硬件的潛力,比如 AMD。
需要說明的是,中國不少 AI 硬體平台已經提供 CUDA 兼容能力,或 CUDA 轉譯層。例如,摩爾線程、沐曦、壁仞和天數智芯,都是通過轉譯層實現 CUDA 兼容度較高的中國芯片廠商。因此從理論上說,它們並不一定需要 TileLang。

大規模強化學習與 RSI
隨著 DeepSeek 獲得更多算力來源,也就是可選硬體變多,同時模型本身對計算資源的需求下降,它就能夠推進更有野心的訓練項目,尤其是強化學習後訓練。
強化學習需要生成大量軌跡,也就是生成數萬億 Token。這個過程很快就會變得極其昂貴。更進一步,如果要訓練 100 萬上下文長度的模型,就需要生成同樣長度的軌跡。只有在這種超長軌跡上訓練模型,才能真正支持長周期任務。
此外,由於硬體選項增加,DeepSeek 可調用的硬體資源也會更多,這將推動自動化研究,也就是 RSI。RSI 指的是 AI 自己設計並執行實驗。這種方法會涉及大量試錯,成本也會迅速上升。但 RSI 對探索完整的模型設計空間至關重要。在走向 AGI、乃至隨後走向 ASI 之前,DeepSeek 必須具備 RSI 能力。
DeepSeek 今天做的事,整個行業明天都會跟上
DeepSeek 圍繞專家混合模型、MLA、DSA 等方向的創新,已經被全球和中國的其他 AI 實驗室陸續採用。
例如,GLM 系列模型的開發方 ZAI 就使用了 MLA 和 DSA。Kimi,也就是 Moonshot,也採用了 MLA,並且毫不避諱地表示,其架構是基於 DeepSeek 架構設計的。反過來,DeepSeek 也使用了 Muon 優化器,而 Muon 最早是由 Kimi(Moonshot)在大規模訓練中採用的。
需要說明的是:
MoE 最早由 Google 在 2017 年提出,關鍵作者是 Noam Shazeer。DeepSeek 的貢獻在於將 MoE 大規模應用,並發明了自己的配套技巧。
Muon,即 MomentUm Orthogonalized by Newton-Schulz 优化器,由机器学习研究员 Keller Jordan 于 2024 年底提出。Kimi(Moonshot)团队是第一个将其用于大规模训练的团队。
那賺錢的問題怎麼辦?
我们可以看看 OpenAI 這個有趣的例子。
OpenAI 獲得了以較低價格購買 AMD 和 Cerebras 股票的認股權證 / 選擇權,這些權益與其算力消費里程碑掛鈎。對 AMD 和 Cerebras 來說,這是一筆非常划算的交易。因為一旦 OpenAI 承諾使用它們的硬件,它們長期成功的可能性就會大幅提高。
AMD 公告中有這樣一段話:
「作為協議的一部分,為了進一步協調雙方戰略利益,AMD 向 OpenAI 發行了最多可購買 1.6 億股 AMD 普通股的認股權證,並將根據特定里程碑的達成逐步歸屬。第一批將在初始 1 吉瓦部署完成時歸屬,後續批次則會隨著購買規模擴大至 6 吉瓦而逐步歸屬。歸屬條件還與 AMD 達成特定股價目標,以及 OpenAI 實現讓 AMD 大規模部署所需的技術和商業里程碑掛鈎。」

我預計,DeepSeek 也會與多家中國內存、ASIC、CPU 和網絡技術棧廠商達成類似協議,並與它們深度合作,使這些廠商的硬件棧能夠勝任領先 AI 工作負載。
考慮到所有西方,包括東亞盟友在內的 AI 股票總市值已經遠超 10 萬億美元,這種「通過合作獲得股權回報」的方式,將讓 DeepSeek 有機會幫助中國打造一個同樣巨大的產業,並在其中分得自己的蛋糕,最終實現自身 1 萬億美元估值。
這不僅會讓 DeepSeek 賺到遠超傳統應用訂閱業務的錢,同時也能實現它所說的「讓 AGI 惠及每個人」的目標。梁文鋒是 Jim Simons 的忠實粉絲,也是足夠聰明的資本玩家,他不可能錯過這一點。
如果你回頭看 DeepSeek 至今所做的一切,只有這一種解釋最說得通。
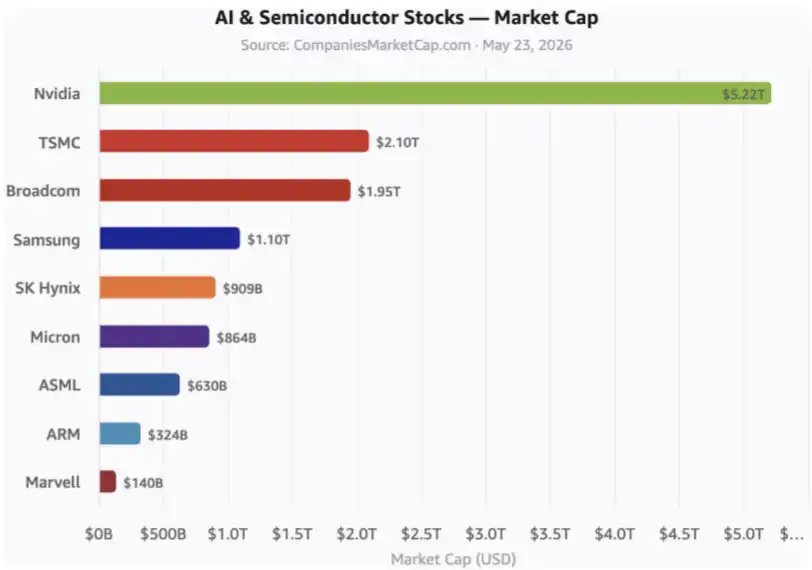
這些是關鍵 AI 股票。圖中還沒有包括 hyperscalers,也就是超大規模雲廠商,以及許多其他相關公司。
[原文連結]
歡迎加入律動 BlockBeats 官方社群:
Telegram 訂閱群:https://t.me/theblockbeats
Telegram 交流群:https://t.me/BlockBeats_App
Twitter 官方帳號:https://twitter.com/BlockBeatsAsia






