

 融資信息
融資信息
 專題
專題
 鏈上生態
鏈上生態
 詞條
詞條
 播客
播客
 活動
活動
 OPRR
OPRR

5分鐘,讓 AI 成為您的第二大腦
原文標題:Claude Code + Obsidian 終極指南(打造 AI 第二大腦)
原文作者:AI Edge
編譯:Peggy,BlockBeats
編者按:本文介紹了一種基於 Claude Code 與 Obsidian 搭建的個人知識系統,其核心不再是傳統 RAG 模式下「每次查詢、臨時檢索」的用法,而是嘗試讓 AI 持續構建並維護一個可演變的知識庫(Wiki)。
從結構上看,該系統可以拆分為三層:
·其一,是原始數據層,包括筆記、文章、轉錄內容等不可修改的輸入源;
·其二,是由 AI 維護的結構化知識庫,在持續更新中完成交叉引用與關係構建;
·其三,是 Schema 規則層,用於規範知識的組織方式與系統運作邏輯。
圍繞這一結構,系統通過三類核心操作運行:Ingest(攝取),將外部信息不斷納入體系;Query(查詢),實現對知識的即時調用;Lint(校驗),用於檢查結構一致性並修復潛在問題。
在這一機制下,知識不再停留於一次性對話結果,而是通過「寫入—整理—再利用」的循環,逐步沉澱為可復用的長期資產。作者據此提出,這種模式使知識具備類似「複利」的積累效應:一方面減輕個體的認知負擔,另一方面提升模型輸出的準確性與上下文一致性。
但這一系統的有效運行,也建立在一個前提之上——持續輸入與維護。如果缺乏穩定的數據注入與結構更新,這一「第二大腦」將難以形成真正的積累效應,其優勢也將隨之減弱。
以下為原文:
Claude Code + Obsidian,是我用過最強大的 AI 組合。
我幾乎搭建出了一個「AI 第二大腦」,把我所有的思考、閱讀、寫作、線上研究等內容都納入其中。這裡面包含了我的商業計劃、我發布過的所有 YouTube 影片、寫過的文章,以及一切對我重要的內容。
Claude Code + Obsidian 已經在各個平台上迅速走紅,而且這並非偶然。
對我個人來說,這套 AI 系統極大地減輕了我的認知負擔,讓我能夠把精力集中在真正重要的事情上——無論是業務,還是個人生活。

我的 Claude Code + Obsidian 系統
這套系統看起來也許有點複雜,但實際上搭建只需要 5 分鐘。更關鍵的是,它自帶記憶機制,會隨著使用不斷自我優化。
接下來,我會一步一步帶你復刻這個「AI 第二大腦」系統,它確實能實實在在地提升你的效率。
建議你讀到文章最後——我會附上一份完整的 Claude Code + Obsidian 操作速查表,以及文中提到的所有資源(全部免費)。
開始之前
這套系統並非我一人原創,它的靈感來自 Andrej Karpathy 幾天前關於「LLM 知識庫」的一條爆火推文。
相關閱讀:https://x.com/karpathy/status/2039805659525644595
這條推文之所以迅速走紅,是因為它為解決當前 AI 發展中的一個關鍵痛點提供了思路。
這個問題就是:每當你開啟一段新的對話,或者切換到新的 AI 工具時,都不得不反覆重新輸入提示詞、補充上下文,幾乎等於從零開始。
而將這一套系統提示詞,與 Obsidian 和 Claude Code 結合起來之後,這個問題可以被徹底解決,同時還能顯著提升 AI 的輸出質量。
這個系統是如何運作的?
整個系統由四個核心模組構成:
1、你的資料:包括文章、筆記、轉錄內容、靈感想法等
2、組織方式:通過 Claude Code 在 Obsidian 中自動完成整理
3、即時調用:你可以隨時向這個「資料庫」提問,獲得答案
4、進化記憶:系統會隨著使用不斷變得更聰明
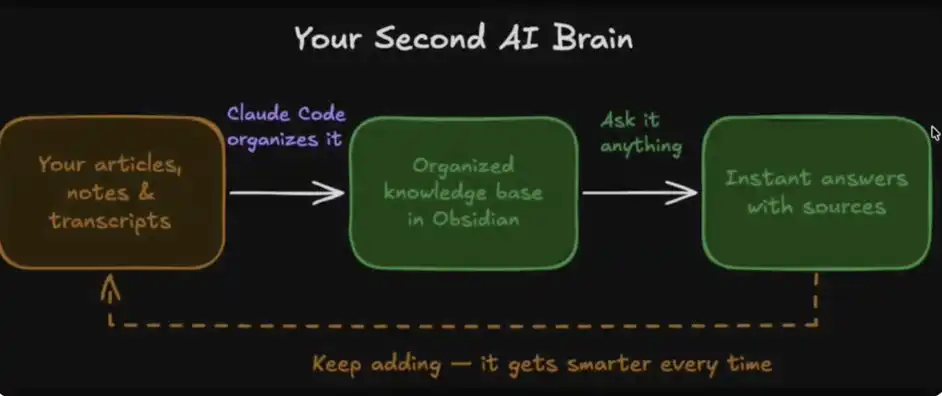
你的 AI 第二大腦
這套系統的真正力量在於什麼?
作為人類,我們的認知帶寬是有限的。我們會遺忘,有時也很難把不同的想法連接起來,能同時跟蹤和處理的信息終究是有上限的。
而借助這套由四個模組組成的系統,你實際上是在釋放自己的認知負擔,把「連接、整理與理解信息」的工作交給 Obsidian 和 Claude Code。
你的想法開始被系統性地串聯起來,一條筆記可以自動關聯到另一條筆記,而你可以隨時通過 Claude 將這些內容重新提取、組合和調用。
在這種結構下,你的知識不再是零散的,而是一個可以被不斷調用和重組的網路——幾乎沒有上限。
如何在 5 分鐘內搭建你的 AI 大腦
1、下載 Obsidian
https://obsidian.md/
2、創建你的 Vault(知識庫)
下載完成後,Obsidian 會提示你創建一個「Vault」。
你可以把它理解為電腦上的一個文件夾,我們會在這裡存放所有內容,並讓 Claude Code 訪問和管理這些數據。
這個 Vault 的名稱可以隨意設定——比如我自己就叫它「Obsidian Vault」。
Obsidian Vault(知識庫)
這個 Vault,就是 Obsidian 用來存儲你所有數據與筆記的地方,所有內容都會以 MD(Markdown)文件的形式保存。
3、設置 Claude Code
接下來,你需要配置一個可以訪問 Claude Code 的方式。對我來說(也很可能對大多數人而言),最簡單的方法就是直接使用桌面客戶端。
在主聊天界面中,點擊「選擇文件夾」,然後找到你剛剛創建的 Obsidian Vault 並選中它即可。
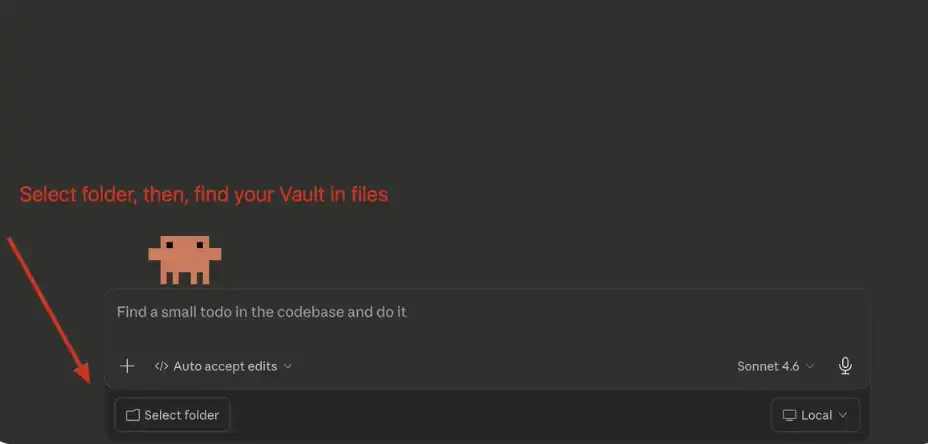
Claude Code:連接你的 Vault
4、設置系統提示詞(System Prompt)
當你選好文件夾之後,下一步就是把 Andrej Karpathy 的系統提示詞粘貼到主聊天框中。
你可以在這裡複製這段提示詞:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f

你的輸入應該是這樣的:
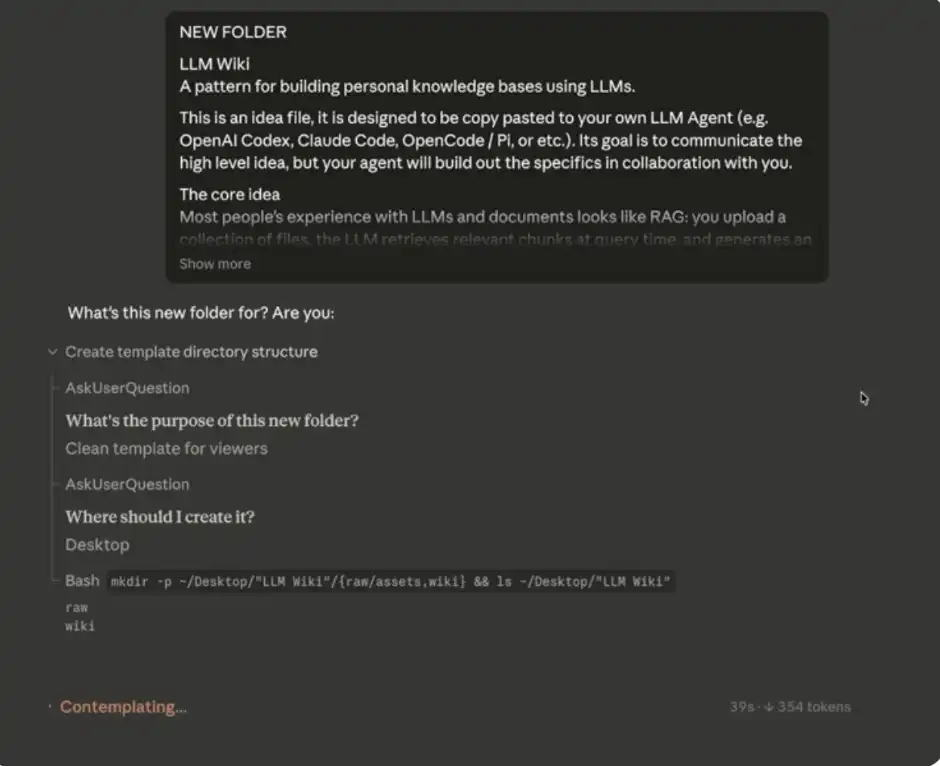
Claude Code 初始輸入
小提示:如果你不想,也完全可以不用手動打開 Obsidian。只要把 MD 文件夾(也就是你的 Vault)以及相關數據交給 Claude Code,它就可以直接對這些文件進行讀寫和修改——而這些內容會自動同步到你的 Obsidian「第二大腦」中。
5、構建你的數據庫
當你輸入完上述的系統提示詞之後,Claude Code 會開始向你詢問一些數據來源,用來初始化並逐步填充你的「第二大腦」。
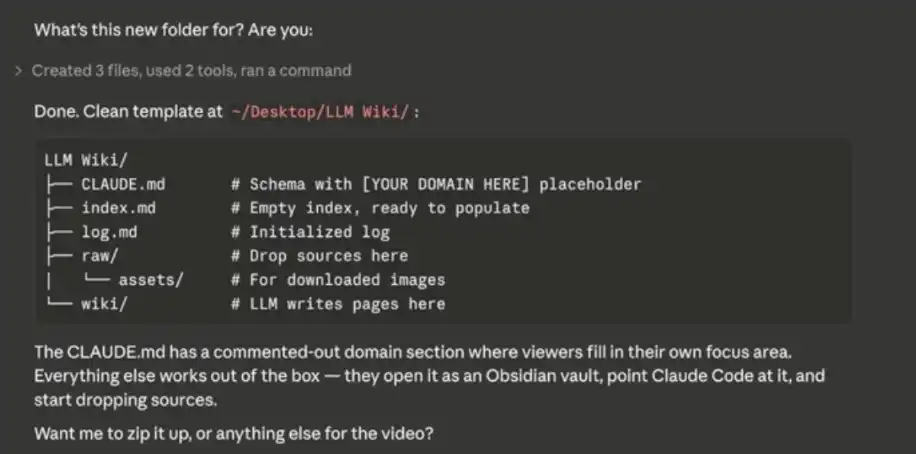
構建你的數據庫
你可以將 Obsidian 想像成一本「空白筆記本」——一開始需要你主動輸入內容,資料庫才會逐步建立起來。可以匯入的內容包括:筆記、CSV 檔案、Markdown / 文本檔案等。
一些實用建議:
·從你現有的筆記工具中匯出資料
·如果你使用 Notion,可以匯出為 CSV 檔案
·讓 Claude(或其他大型模型)整理一份關於你的資訊,用來初始化你的「第二大腦」
·把你已有的文章、收藏、靈感想法等一次性匯入進來——這是建立初始資料的最好時機,後續也可以隨時補充
需要注意的是,像我這樣數據量較大的資料庫,並不是一蹴而就的,而是隨著時間不斷輸入、逐步積累形成的。

我的資料庫
就是這樣,你的「AI 第二大腦」已經搭建完成,可以開始運行了。接下來,我再分享一些進階技巧,幫你把它用得更高效。
進階技巧(Pro Tips)
1、Obsidian Chrome 擴充外掛
如果你想更輕鬆地往系統裡添加資料,只需要安裝 Obsidian 的 Chrome 擴充功能。它可以讓你在瀏覽網頁時,直接點擊「Add to Obsidian(添加到 Obsidian)」,把內容一鍵保存進你的知識庫。這會讓你構建「第二大腦」的過程變得非常順手。
我自己也經常用這個功能來收集文章、網頁資料、研究資料等等。
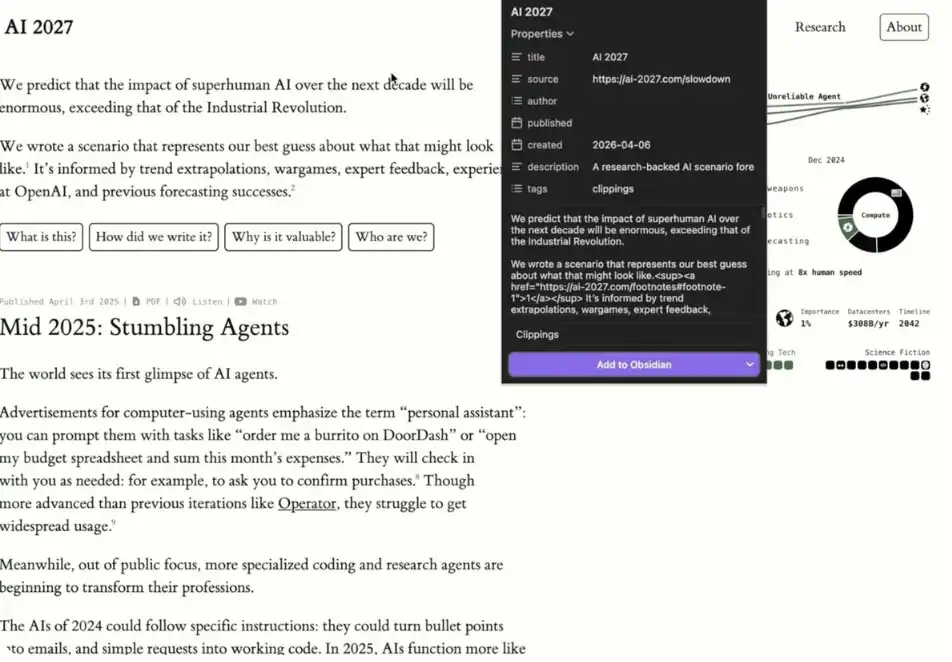
示例:使用 Obsidian Chrome 擴充外掛
需要注意的是,通過擴充添加的資料,最初只是一個「孤立的資料來源」。
接下來你可以告訴 Claude Code:「我剛剛在 Obsidian 裡添加了 [x],請幫我把這些內容整合進我的 Wiki。」
Claude Code 會自動將這些新資料與已有內容建立關聯、生成連結,讓它真正融入你的「第二大腦」。這也是這套工具組合強大的原因所在。
2、分開建立資料夾(Vault)
Andrej Karpathy 建議使用兩個獨立的資料夾(Vault):
·一個用於工作 / 商業內容
·一個用於個人生活 / 目標管理
我自己的使用體驗也是,這樣的結構最清晰、最有效。
3、實用性
我發現這套系統最有價值的一個用法,其實很簡單:讓你的 LLM 提示詞更精準。
當模型可以訪問你完整的個人信息、商業計劃、寫作背景等上下文時,它就能生成更加「定制化」、更貼近現實情況的高質量提示詞(甚至是「超級 Prompt」)。
當然,這套系統的用途遠不止這些,但如果你只想從一個最實用的場景入手,我會強烈建議你先從「提升 Prompt 質量」開始。
4、Orphans(孤立節點)
在 Obsidian 中,「Orphans」指的是那些沒有與其他筆記建立連接的數據點。
這個功能很有用,因為它可以幫你:
·找到尚未被整合的想法
·發現數據庫中的「薄弱區域」
·判斷哪些內容值得進一步擴展或深化
換句話說,它不僅是一個整理工具,也是一個幫助你發現思考盲區的機制。

Orphans(孤立節點)
你可以在右上角點擊「三個點」,找到並開啟 Orphans 的開關,用來查看哪些內容還沒有建立關聯。
這套系統的潛在缺點
前面我們已經講了很多優點、使用場景和優化方法,那麼它的不足是什麼?什麼情況下你不太適合使用這套系統?
1、不習慣可視化的人
這套系統的一個核心優勢,是可以將數據進行可視化呈現。如果你本身並不依賴或不習慣這種方式,那它對你的幫助可能會比較有限。
2、需要一定維護成本
如果你不願意持續維護一個資料庫,那這套系統可能不適合你。雖然維護成本並不高,但如果不持續往「第二大腦」中輸入數據,它就很難發揮價值。
3、存儲佔用
所有內容都會以 Markdown 檔案的形式存儲在本地,這會佔用一定的裝置空間。這一點也需要提前考慮。
[原文鏈接]
歡迎加入律動 BlockBeats 官方社群:
Telegram 訂閱群:https://t.me/theblockbeats
Telegram 交流群:https://t.me/BlockBeats_App
Twitter 官方帳號:https://twitter.com/BlockBeatsAsia



